Raft 算法
Raft 作为经典的分布式一致性算法,旨在实现多节点状态机的高可靠一致性。
Raft 算法由 leader 节点来处理一致性问题,并分为了以下几个子问题:
- leader 选举:集群中必须存在一个 leader 节点。
- 日志复制:leader 节点接收来自客户端的请求,然后将这些请求序列化成日志数据再同步到集群中其它节点。
- 安全性(幂等性):如果某个节点已经将一条提交过的数据输入 raft 状态机执行了,那么其它节点不可能再将相同索引的另一条日志数据输入到 raft 状态机中执行。
两个重要机制
- 角色转换与选举机制:Raft 将系统中的节点分为 Leader、Follower 和 Candidate 三种角色。系统启动时,所有节点都是 Follower,Follower 会定期从 Leader 处接收心跳信息以确认 Leader 的存活。如果 Follower 在一段时间内(选举超时时间)没有收到 Leader 的心跳,它会转变为 Candidate,发起新一轮的选举。Candidate 向其他节点发送请求投票消息,其他节点根据收到的请求投票消息,决定是否为该 Candidate 投票。当 Candidate 获得超过半数节点的投票时,它就成为新的 Leader。Leader 会周期性地向所有 Follower 发送心跳消息,以维持自己的领导地位。每个 Leader 的领导周期称为一个任期(Term),任期号是单调递增的。
- 日志复制机制:客户端的请求会被 Leader 作为日志条目添加到自己的日志中。Leader 将新的日志条日复制到其他 Follower节点。它会通过附加日志消息将日志条目发送给 Follower,Follower 收到消息后会将日志条目追加到自己的日志中,并向 Leader 发送确认消息。当 Leader 得知某个日志条目已经被大多数节点复制时,它会将该日志条目标记为已提交,并将其应用到状态机中。然后,Leader 会通知其他节点该日志条目己提交,Follower 也会将已提交的日志条目应用到自己的状态机中。
Leader 选举
对于 Raft 集群,可以简单理解为 Leader 负责统领所有 Follower,如果 Leader 出现故障,整个集群都会对外停止提供服务,直到选举出下一个 Leader。
Q1:Follower 如何知道 Leader 出现了故障?
A2:Leader 会定时向集群中的 Follower 节点发送 AppendEntry RPC(作为心跳)以表明自己仍然存活。那么,如果一段时间后(即选举超时时间,每一个 Follower 都是随机的),某个Follower 没有收到 Leader 发来的 AppendEntry RPC,那么该 Follower 就会认为当前的 Leader 出现了故障,从而转换成 Candidate 发起选举。
ps:“Follower 在一段时间内没有接收到 Leader 发送的 AppendEntry RPC“,具体可以利用定时器和一个标志位实现,每到定时时间就检查这期间内有无 AppendEntry RPC 即可。
ps:AppeandEntry RPC 的两个主要作用和一个附带作用:
- 主要作用:
- 充当心跳
- 携带日志 entry 及其辅助信息,以控制日志的同步和日志向状态机提交
- 附带作用:通告 Leader 的 index 和 term 等关键信息,以便 Follower 对比确认自己或者 Leader 是否过期。
Q2:Follower 知道 Leader 出现故障后如何选举出新 Leader?
A2:当某个 Follower 认为 Leader 故障后,它会将 term 加一,变成 Candidate,向其他节点发起 RequestVote RPC 来争取其他 Follower 的选票,过一段时间后会发生如下两种情况:
- 赢得选举(即获得超过半数的选票),成为 Leader。但如果发现已经有符合要求的 Leader,自己会退回成 Follower,这个符合要求包括:Leader 的 term >= 自己的 term。
- 一轮选举结束,无人成为 Leader(可能的原因是恰好有两个 Follower 选举超时时间一样,那么他们同时发起选举,谁都没有获得超过半数的选票),那么就重复这个过程,即:term 加一,选举超时时间最短(每个 Candidate 在发起选举后,都会随机生成一个新的选举超时时间,因此虽然刚才恰好有两个 Follower 超时时间相同,但这一轮大概率不会了)的那个 Follower 变成 Candidate,发起选举。
Q3:符合什么条件的 Candidate 可以获得选票,成为 Leader?
A3:当 Candidate 发送 RequestVote RPC 时,会带着自己最后一条 entry 的信息。所有节点收到该请求后,都会与自己的日志对比,如果发现自己的日志更新一些,则会拒绝投票给该 Candidate,即自己的日志必须要“不旧于”发起投票的 Candidate 的日志。
判断日志新旧的方法:比较最新日志 entry 的 term 和对应的 index(index 即日志 entry 在整个日志中的索引)。先判断 term,再判断 index。如果两个节点最新的日志 entry 的 term 不同,那么 term 大的日志新;如果最新的日志 entry 的 term 相同,那么 index 大的日志新。
这样的限制可以保证:成为 Leader 的节点,其日志是所有节点中最完备的,即包含了整个集群中所有的 committed entries(已提交的日志条目)。
日志同步与心跳
日志同步和心跳是放在同一个 RPC(AppendEntry RPC)中实现的,因为心跳 RPC 可以看成是没有携带日志的特殊日志同步 RPC。
对于一个 Follower,如果 Leader 认为其日志已经和自己完全匹配了,那么在 AppendEntry RPC 中就不用携带日志了(再携带日志属于无效信息了,但其他信息依然要携带),反之如果 Follower 的日志只有部分匹配,那么就需要在 AppendEntry RPC 中携带对应的日志。
Q1:为什么不直接让 Follower 拷贝 Leader 的所有日志?
A1:Leader 发送 AppendEntry RPC 的目的是让 Follower 同步自己的日志,当然可以让 Leader 发送自己的全部日志给 Follower,然后 Follower 接收后覆盖掉自己原有的日志,但是这样就会携带大量无效的日志(即 Follower 本身就有的那些 entry)。因此 Raft 的做法是:先找到日志不匹配的那个点,然后只同步那个点之后的日志。
Q2:Leader 如何知道 Follower 的日志是否与自己完全匹配?
A2:在 AppendEntry RPC 中携带上 entry 的 index 和对应的 term,通过比较最后一个日志的 term 和 index 来得出来某个 Follower 的日志是否匹配。
Q3:如果发现不完全匹配,那么如何找到哪部分日志是匹配的,哪部分日志是不匹配的?
A3:Leader 每次发送 AppendEntry RPC 后,Follower 都会根据其 entry 的 index 和对应的 term 来判断某一个日志是否匹配。在 Leader 刚当选时,会从最后一个日志 entry 开始判断是否匹配。如果匹配,那么后续发送 AppendEntry RPC 就不需要携带日志 entry 了;如果不匹配,那么下一次就发送倒数第2个日志 entry 的 index 和其对应的 term 来判断匹配,如果还不匹配,那么依旧重复这个过程,即发送倒数第3个 日志 entry 的相关信息。重复这个过程,直到遇到一个匹配的日志 entry,即找到了临界点。
三个重要概念
- log(日志):客户端请求的外部命令是以 log 保存的。
- entry(条目):日志可以看成是一个连续的数组,其中的一条就是 entry。
- term(任期):作为内部逻辑时钟,使用 term 的对比来比较日志、身份、心跳的新旧,term 用连续的数字进行标识。
Raft 日志的两个特点:
- 两个节点的日志中,有两个 entry 拥有相同的 index 和 term,那么它们一定记录了相司的内容/操作,即两个日志 entry 匹配。
- 两个节点的日志中,有两个 entry 拥有相同的 index 和 term,那么它们前面的日志 entry 也相同。
如何保证这两点:
- 保证第一点:仅有 Leader 可以生成 entry。
- 保证第二点:Leader 通过 AppendEntry RPC 和 Follower 通讯时,除了带上自己的 term 等信息外,还会带上 entry 的 index 和对应的 term 等信息。Follower 接收到后,通过与自己的对比就可以知道自己与 Leader 的日志是否匹配,不匹配则拒绝请求。Leader 被 Follower 拒绝后就明白是 entry 不匹配,那么下一次就会尝试匹配前一个 entry,直到遇到一个 entry 匹配,并将不匹配的 entry 给删除(覆盖掉)。
Term 与 Leader 身份绑定,Term 会在 Candidate 发起选举的时候加1(无论选举成功与否),对于一次选举可能存在两种结果:
- 胜利:即超过半数的节点认为当前 Candidate 有资格成为 Leader,给它投了选票。
- 失败:没有任何 Candidate 获得超半数的选票,那么选举超时之后又会开始另一个 Term + 1的选举。(可能的原因是:一个 Term 的 Leader 只有一位,虽然各个节点的选举超时时间是随机的,但如果两个节点恰好同时发起选举,也就是某个 Term 的 Candidate 有多位,那么不可能有两个节点同时获得超过半数的选票)
Q:Raft 如何保证一个 Term 中最多只有一个 Leader ?(也可能有零个,即选举失败的情况)
A:Candidate 变成 Leader 的条件是获得超过半数(总节点数的半数以上,而不是存活节点的)选票(Raft 节点数量为奇数,Candidate 默认投给自己一票),一个节点在一个 Term 内只有一张选票,因此不可能有两个或以上节点同时获得超过半数的选票。
当某个节点发生故障时,它无法知道当前最新的 Term 是多少。在故障恢复后,节点可以通过其他节点发送过来的心跳查看最新 Term。当发现自己的 Term 小于最新 Term 时,这意味着自己已经过期,不同身份的节点处理方式有所不同:
- Leader 和 Candidate:退回成 Follower 并更新 Term 到较大的那个 Term。
- Follower:更新 Term 到较大的那个 Term。
Q:为什么 Leader 和 Candidate 发现自己的 Term 小于其他节点时会退回成 Follower,而不是延续身份?
A: 因为通过 Term 信息知道自己已经过期,意味着自己可能发生了网络隔离等故障,那么在此期间整个 Raft 集群可能已经有了新的 Leader、提交了新的日志,那么此时自己的日志就是有缺失的,如果不退回成 Follower 可能会导致整个集群的日志缺失,不符合强一致性。
ps:详见 Raft 深层剖析
共识
共识是容错分布式系统中的一个基本问题,涉及多个服务器对状态机状态(上层的 KV 数据库)达成一致。一旦超过半数的机器对状态机做出了同一个决定,那么这个决定就是最终决定。如果有少于一半的机器出现故障,集群可以正常运行;如果超过一半的机器出现故障,那么集群将停止对外提供服务,但不会盲目返回错误的结果。
共识算法要满足的性质:
- 在非拜占庭条件下保证共识的一致性。非拜占庭条件就是可信的网络条件,即与你通信的节点的信息都是真实的,不存在欺骗。
- 在多数(超过半数)节点存活时,保持可用性。“多数”永远指的是配置文件中所有节点的多数,而不是存活节点的多数。
- 不依赖于绝对时间。共识算法要应对出现故障的情况,在这样的环境中网络报文很可能会受到干扰而延迟,因此不能完全依靠绝对时间。Raft 用自定义的 Term 作为逻辑时钟来代替绝对时间。
- 在多数节点达成一致后就返回结果,而不会受到个别慢节点的影响,即只要大多数节点同意操作,就代表整个集群同意该操作。对于 Raft 来说,操作是存储到 log(日志)中,一个操作就是 log 中的一个 entry(条目)。
有一个常见的误解:使用了 Raft 或者 paxos 算法的系统都是线性一致的(Linearizability,即强一致),其实不然,共识算法只能提供基础,要实现线性一致还需要在算法之上做出更多的努力。
一致性(Consistency)的含义比共识(consensus)要宽泛,一致性指的是多个副本对外呈现的状态。包括顺序一致性、线性一致性、最终一致性等。而共识特指达成一致的过程,但注意,共识并不意味着实现了一致性,一些情况下他是做不到的。
Raft 是 CP 系统,保证了强一致性和分区容忍性,但牺牲了部分高可用性。比如:当 Leader 节点出现故障后,系统需要一段时间进行重新选举,这段时间系统处于不可用状态。
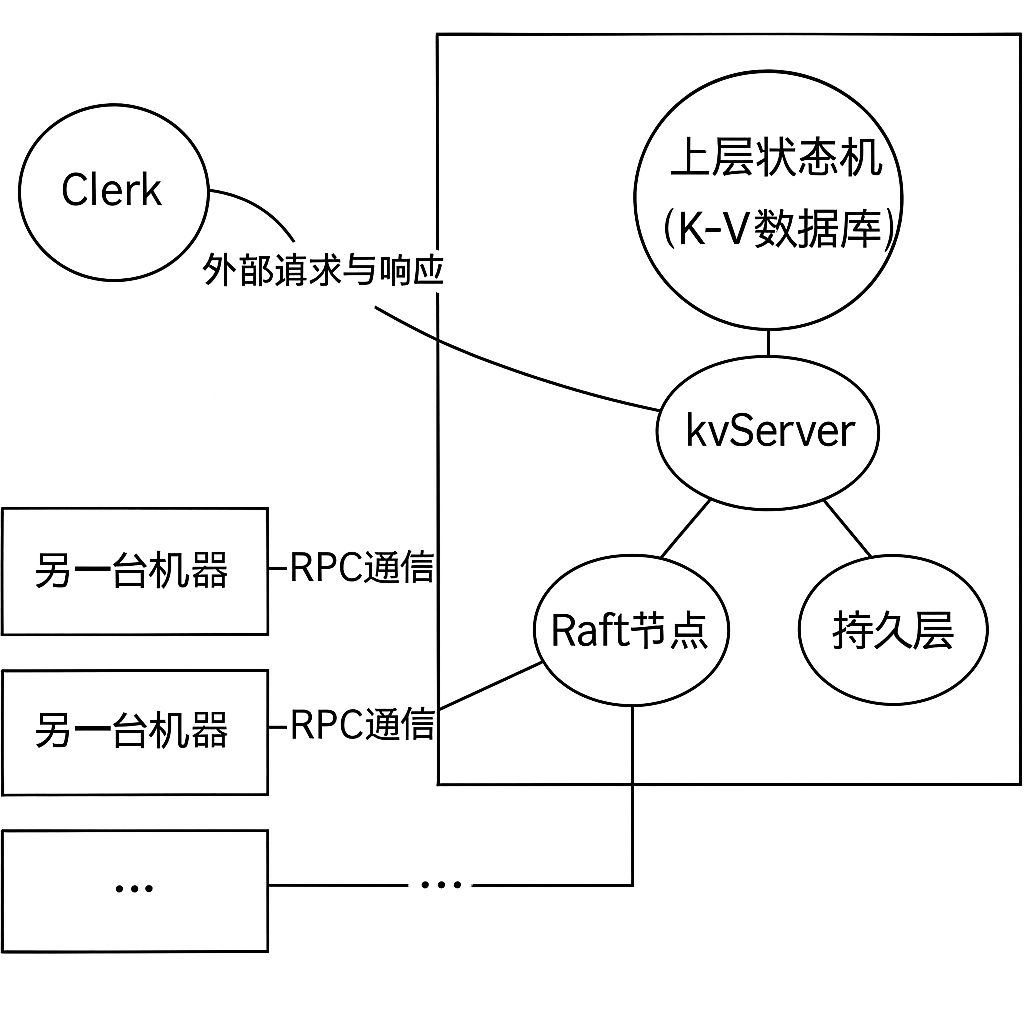
宏观架构
- Raft 集群
- Raft 节点:Raft 算法的实现核心,负责与集群中的其他 Raft 节点沟通,达到分布式共识的目的。
- kvServer:负责 Raft 节点、KV 数据库和 Clerk 客户端之间的协调服务,相当于三者之间的桥梁;还负责持久化 KV 数据库中的数据。
- 持久层:负责相关数据的落盘。对于 Raft 节点,对一些关键数据(比如日志)进行落盘处理,以保证节点宕机重启后可以恢复关键数据;对于 kvServer,对 KV 数据库的数据进行落盘处理。
- Clerk :客户端(Leader 节点负责处理客户端请求,不过要通过 kvServer)
- 上层状态机(KV 数据库):负责数据存储。
- RPC 通信框架:为 Leader 选举、日志复制、数据查询、心跳发送等多个操作提供多节点、简单快速的通信功能。
一次请求的简化流程图:
客户端请求 (Put / Get / Append)
↓
KvServer::PutAppend() / Get()
↓
KvServer → Raft::Start() 发起日志追加请求
↓
Raft (复制日志,达成多数派一致)
↓
applyChan.push_back(ApplyMsg) ← KvServer::ReadRaftApplyCommandLoop()
↓
应用日志命令到 m_skipList / kvDB
↓
回复客户端(通过回调 / 结果通道)Raft 代码
Raft 的主要流程
初始化节点
init():初始化一个 Raft 节点,对任期、身份、日志提交索引等关键状态进行初始化;如果有快照就从持久化中恢复;启动三个定时器:
- leaderHearBeatTicker:Leader 周期性发送心跳(默认25ms,一般比选举超时小一个数量级)。
- electionTimeOutTicker:Follower 检测选举超时(随机,在300~500ms之间)。
- applierTicker:定期将日志应用到状态机中(默认10ms)。
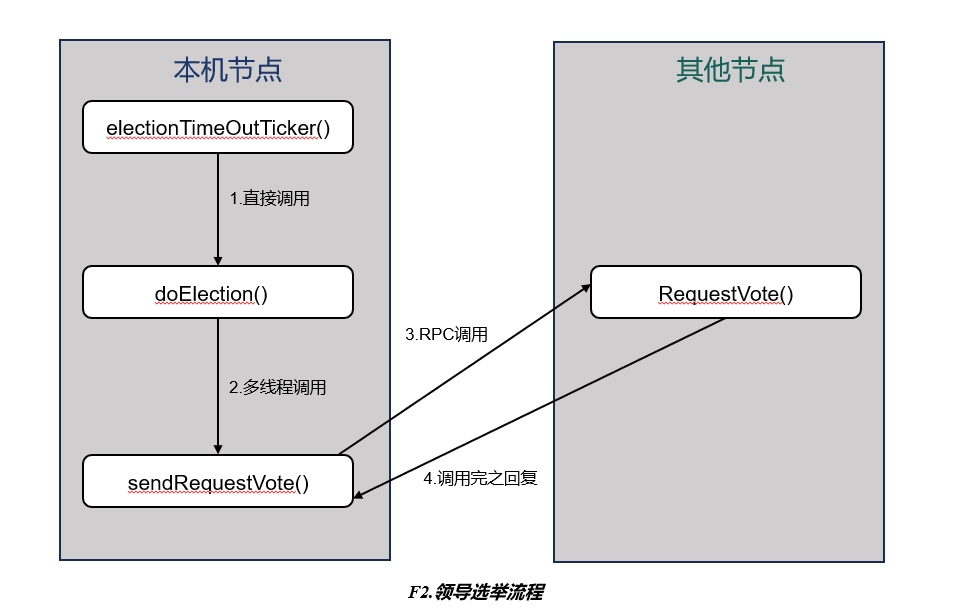
领导选举
见下图 F2.领导选举流程
electionTimeOutTicker():负责判断是否该发起选举,如果该就执行 doElection() 发起选举。- 在死循环中,首先计算距离下一次超时应该睡眠的时间(即上次重置选举计时器的时间 + 随机化的选举超时时间 – 当前时间),然后睡眠这段时间。若醒来后发现在睡眠期间选举的超时定时器被重置,则继续循环;若没有被重置,则调用 doElection() 触发选举。
- 选举超时定时器是否重置的条件是:收到 Leader 发来的 AppendEntryRPC(日志同步和心跳)或给其他节点选举投票。
doElection():实际发起选举,在选举定时器超时时调用。构造需要发送的 RPC(即 RequestVote RPC),并创建多线程调用 sendRequestVote() 处理 RPC 及响应。- 1.状态由 follower 转换为 candidate
- 2.任期 +1
- 3.给自己投票
- 4.征求其他节点的票
- ps:当选举的时候定时器超时就必须重新选举,不然会因为没有选票而卡住,term 也要增加。
sendRequestVote():负责发送选举 RPC,并接收和处理对端发送回来的响应。- 向指定的节点发送 RequestVote RPC 请求。
- 检查 RPC 的返回结果,并进行选举投票结果统计。
- 如果回复节点的 term 比自己的大,说明自己落后了,就退回到 follower 状态并把 term 更新为较大的那个(只要修改了状态就要持久化)。
- 如果 term 一样,则判断对方是否把票投给了自己。
- 如果获得过半选票,则将自身转变为 leader 并初始化领导者状态。
- 维护对每个 follower 的日志同步信息:
- m_nextIndex[i] = lastLogIndex + 1; // 下一次要发送的日志条目索引
- m_matchIndex[i] = 0; // 表示 follower 最后匹配的日志条目,每换一个领导都要从0开始
- 开始发送心跳
- 持久化
- 维护对每个 follower 的日志同步信息:
RequestVote():接收别人发来的选举请求,检验是否要给对方投票,并将决定回复给对方。- 如果候选者的 term 比自己小:说明出现过网络分区,他已经过时了,拒绝给他投票。
- 如果候选者的 term 比自己大:说明出现过网络分区,我已经过时了,更新自己的 term(是否给他投票还要看后面)。
- 两节点 term 相同,比较日志新旧,如果候选者的日志不旧于自己的日志,考虑给他投票。
- 判断自己本轮投票是否已经投给过别人,如果没有,投给该候选者。
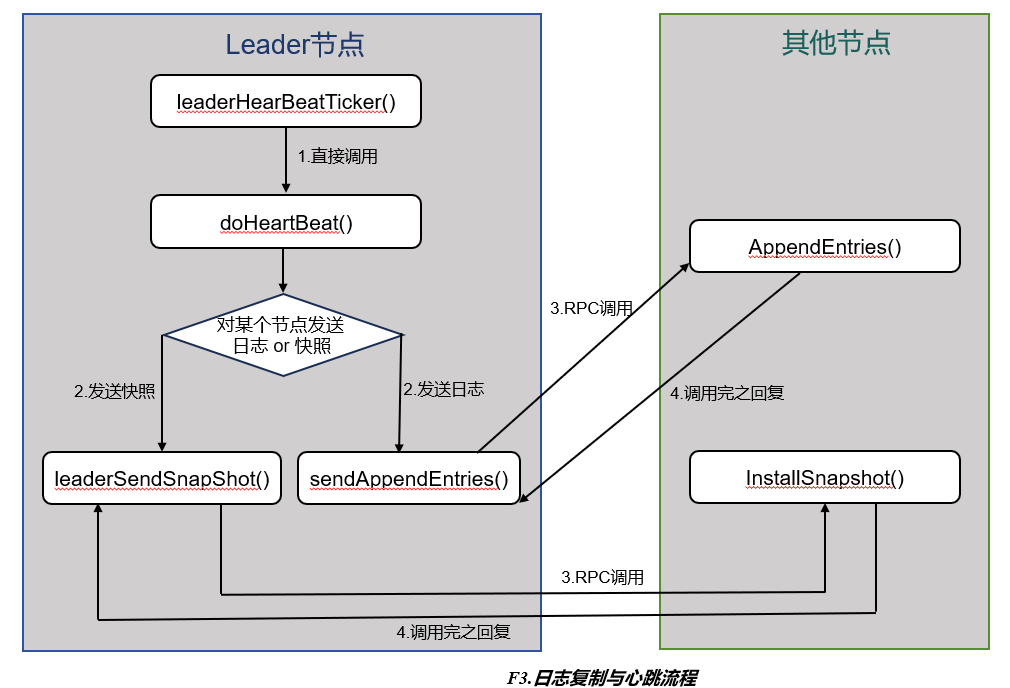
日志同步和心跳
见下图 F3.日志复制与心跳流程
leaderHearBeatTicker():负责判断是否该发送心跳,如果该发送就执行 doHeartBeat()。std::chrono::duration<signed long int, std::ratio<1, 1000000000>> suitableSleepTime{};- 使用
std::chrono(可弱 no)时间库定义了一个纳秒级别的时间段(duration)对象,并且默认初始化为 0 纳秒。
- 使用
- 目的是为了让负责心跳定时器的线程睡眠,避免线程频繁检查心跳是否被重置,导致 cpu 空转。
- 睡眠时间计算公式 = 上一次心跳时间点 + 心跳周期 – 当前时间
- 如果在睡眠的这段时间内定时器被重置过(即 lastRestHearBeatTime > 睡眠前取的“当前时间”wakeTime)则继续保持睡眠,如果没有就会执行实际的心跳操作。
- Leader 为什么要考虑定时器重置,直接按固定间隔
HeartBeatTimeout发送心跳不就好了?- 因为在实际实现中,追加日志条目和心跳都属于 AppendEntries RPC,心跳可以看成数据为空的 AppendEntries RPC。那么在心跳睡眠期间,如果 Leader 向 Follower 发送 AppendEntries RPC 进行日志同步,也视为发送了心跳(因为心跳本质就是告诉别人自己还在),所以在睡眠期间心跳定时器可能会被重置。
- 睡眠逻辑和选举定时器 electionTimeOutTicker 的设计基本一致,唯一不同之处在于周期时间,这里心跳间隔时间设置为固定的 25毫秒,而 electionTimeoutTicker 是根据 getRandomizedElectionTimeout() 在 300~500 毫秒之间随机获取的。
doHeartBeat():for 循环向每个 follower 发送心跳(空的 AppendEntries RPC)或日志条目(同步日志)或启用新线程发送快照(如果 follower 落后太多),并更新 m_lastResetHearBeatTime,用于心跳节奏控制。- 判断是否发送快照:
if (m_nextIndex[i] <= m_lastSnapshotIncludeIndex)m_nextIndex[i]:表示 Leader 要发送给该 follower 的下一条日志索引m_lastSnapshotIncludeIndex:Leader 最新快照包含的最后(最新)一条日志索引- 说明 follower 太落后,leader 的日志中已经没有对应条目了 ➜ 只能发快照
- 启动线程发快照就不用再发送 AppendEntries RPC 了,直接 continue 跳过这次循环。
- 准备 AppendEntries RPC(日志同步)
- 构造 AE 参数结构体
- appendEntriesArgs->set_term(m_currentTerm); // 任期
- appendEntriesArgs->set_leaderid(m_me); // ID
- appendEntriesArgs->set_prevlogindex(preLogIndex); // 该 follower 最后匹配的日志条目的索引
- appendEntriesArgs->set_prevlogterm(PrevLogTerm); // 该 follower 最后匹配的日志条目的任期
- appendEntriesArgs->set_leadercommit(m_commitIndex); // leader 已提交的最新的日志索引
- appendEntriesArgs->clear_entries(); // 防止有残留的日志条目信息和新的一起发送出去
- 构造该发送的日志条目
if (preLogIndex != m_lastSnapshotIncludeIndex)- 如果最后匹配的日志条目不是快照的最后一个条目,就在匹配点开始发
- 否则,就从头开始发(即
m_logs中的全量条目,因为再之前的条目已经进快照了,所以在数组中被清除了) - 我设置的制作快照阈值为 0.6,数据库总大小为5000字节(测试时阈值为 0.1,数据库总大小为500字节)。
- 每个节点都有权利生成快照,把需要持久化的内容存到本节点的上层数据库。
raftRpcProctoc::LogEntry* sendEntryPtr = appendEntriesArgs->add_entries();// 追加一个空的LogEntry到entries中,并返回一个指向它的指针,方便立刻赋值。*sendEntryPtr = m_logs[j];// 将日志条目数据深拷贝给新添加的日志条目
- 断言保证发送的日志条目数量正确
- 构造返回值 AppendEntriesReply
- 构造 AE 参数结构体
- 发送 AppendEntries RPC
std::thread t(&Raft::sendAppendEntries, this, i, appendEntriesArgs, appendEntriesReply,appendNums);- 针对每个 follower 都创建一个新线程并传递参数执行函数
- 更新最后一次心跳时间:
m_lastResetHearBeatTime = now()
- 判断是否发送快照:
sendAppendEntries():负责发送日志的 RPC,在发送完后还需要负责接收并处理对端发送回来的响应。- 1. 调用 RPC -> 检查 ok?
ok == false表示 RPC 连接失败(网络中断、宕机等)。- 所以如果连 reply 都没拿到,就直接返回 ok,也就是 false。
- 2. 检查 reply->appstate() == Disconnected?-> 是则返回
- 虽然 RPC 通了,拿到 reply 了,但对端状态不正常(比如在恢复中),就不继续处理了,直接返回 false。
- 3. 检查 term
- 如果
reply->term > m_currentTerm,说明自己这个 leader 落后了,因此降级为 follower,更新 term 和 votedFor,并persist()持久化状态。 - 如果
reply->term > m_currentTerm,说明对方这个 follower 落后了,之前的日志可能都没同步,直接不要它的票(注意跟选举不同,即使 follower 落后,candidate 依然会要票,但 follower 不一定会给票)。 - 之后的情况就都是两个 term 一致了。
- 如果
- 4. 如果自己已经不是 Leader -> 返回
- 5. 检查
reply->success()- 如果是
false:表示与该 follower 的日志不匹配 → 说明它比 leader 落后 → leader 需要不断倒退重试找到共同前缀(匹配点) → 然后一次性把剩下的日志复制过去。 - 如果是
true:表示日志匹配,更新matchIndex和nextIndex,并*appendNums++,表示有一个 follower 同步成功。
- 如果是
- 6. 检查提交条件
- 条件一:超过半数 follower 成功复制(
*appendNums >= 1 + m_peers.size() / 2)。 - 条件二:
entries_size > 0:确保不是空心跳。 - 条件三:要提交的日志条目的 term 与当前 leader 的 term 相等。
- Raft 协议明确规定:只有当前任期的日志条目才能被 Leader 提交。
- 之前 term 的日志条目,即使被多数复制了,也不能单独被提交,必须和当前 term 的日志一起被提交。
- 原因:防止一个老 Leader 在旧任期下提交了无法保证安全性的日志。
- ps:当然 leader 的 term 与该 follower 的相等、日志匹配成功、当前身份是 leader 这些也算条件,不过已经在前面过滤过了。
- 条件一:超过半数 follower 成功复制(
- 7. commit 提交(即更新
m_commitIndex)
- 1. 调用 RPC -> 检查 ok?
AppendEntries1():接收 Leader 发送的日志请求 RPC,检查当前日志是否匹配并进行同步。- 1. 接收请求,设置回复 RPC 的初始状态
reply->set_appstate(AppNormal);- follower 已经收到了 leader 的请求,说明当前能正常接收请求(网络正常)。
- 2. Term 检查
- 如果 leader 的 term 比自己小,则拒绝过期 leader 的请求。将返回状态设置为 false,把自己较新的 term 传给 leader,直接返回。
- 如果 leader 的 term 比自己大,则更新自己落后的状态。但注意不要返回,因为遇到了合法的 leader,要尝试同步日志。
- 依旧三变./
- m_status = Follower; // Raft 原则:发现任期更高的节点,立刻转换为 follower(哪怕本来就是 follower)。
- m_currentTerm = args->term(); // 现在二者的 term 一致了
- m_votedFor = -1; // 如果突然宕机然后上线,理论上是可以投票的
- 依旧三变./
- 之后的逻辑就都是两者 term 一致的情况了。
- 3. 转变为 follower(无论是否已是)
- 假设当前节点是 candidate,它在某个 term(比如 term = 5)发起了选举,在选票未集齐之前,网络中另一个节点也在 term = 5 成功成为了 leader,并开始发
AppendEntries。于是这个 candidate 节点收到该 leader 的 AE 请求后,就要主动退位为 follower。
- 假设当前节点是 candidate,它在某个 term(比如 term = 5)发起了选举,在选票未集齐之前,网络中另一个节点也在 term = 5 成功成为了 leader,并开始发
- 4. 重置选举超时
- m_lastResetElectionTime = now();
- 因为相当于收到了心跳,得知了 leader 的存在,暂时不用选举。
- 5. 前置日志匹配性检查(PrevLogIndex)
- 为什么不能直接从
PrevLogIndex截断日志?一是由于网络延迟,可能收到的是旧 Leader 发来的过期 RPC;二是日志前半匹配,后半冲突的情况。 - 情况一:
args->prevlogindex() > getLastLogIndex()- 这表示我(follower)只保存到了
getLastLogIndex(),你(leader)至少要从这个索引之后的位置开始同步数据。“回退”的逻辑是在 leader 端完成的,follower 只需要告诉 leader 我到哪里了。 - 因此
reply->set_updatenextindex(getLastLogIndex() + 1)并返回 false。
- 这表示我(follower)只保存到了
- 情况二:
args->prevlogindex() < m_lastSnapshotIncludeIndex- prevlogIndex 小于本地快照的最后一个日志索引,说明 leader 发送的日志太旧,已经不存在了。
- 因此
reply->set_updatenextindex(m_lastSnapshotIncludeIndex + 1)并返回 false。
- 下面的逻辑就是已经找到匹配点了。
- 为什么不能直接从
- 6. matchLog() == true
- 即 Follower 缺失的第一个日志条目的前一个条目在本地存在且 term 与 Leader 的 entry term 一致
- ①遍历 Leader 发来的新日志条目
- 如果本地日志中已经有该 index 且 term 一致,则跳过;
- 如果 term 不一致,则替换为 Leader 的日志(Raft 要求 index 相同的日志必须完全相同);
- 如果本地还没有对应的日志 index,直接追加。
- ②commitIndex 同步
- 同步 Leader 的提交进度,不能超过 Leader 的提交位置和本地最后日志位置。
m_commitIndex = std::min(args->leadercommit(), getLastLogIndex());
- ③设置成功响应
reply->set_success(true);
- 7. matchLog() == false
- 表示 Follower 在
PrevLogIndex的日志条目在本地存在,但 term 和 Leader 的这一条目 term 不一致,说明它们的日志在此之前已经产生分歧(比如 leader 接收了日志条目后马上宕机),需要进行日志回退。 - 冲突处理:回退到
PrevLogIndex所在任期的第一个条目,快速回退跳过整个 term 段,而不是一条一条减,起到一个加速的效果。 - Follower 会通知 Leader:请从你这一 term 的第一条日志后开始发并返回 false。
- 表示 Follower 在
- 1. 接收请求,设置回复 RPC 的初始状态
AppendEntries():RPC 接口函数,而上面的AppendEntries1()done->Run()是一个回调,它的作用是 AppendEntries RPC 调用完成后,通知 RPC 框架“我已经处理完这个请求了,可以返回 response 给对方了”。
leaderSendSnapShot():Leader 向 Follower 发送快照 RPC,在发送完后还需要负责接收并处理对端发送回来的响应。- Leader 在发现某个 follower 落后太多(即 follower 的
nextIndex小于 Leader 维护的lastSnapshotIncludeIndex,也就是快照中最后一个日志条目的 index),Leader 就会调用该函数,向该 follower 发送快照以便其能继续追上 Leader 的日志。 - 业务逻辑:
- 1. 构造请求参数 InstallSnapshotRequest args。包括当前 leader 的 id、当前任期、快照的最后一个日志条目的 index 和 term,并从持久化组件中读出快照数据。
- 2. 调用指定
server节点的 InstallSnapshot 接口,发送 RPC 快照。注意在发送 RPC 前释放锁,避免阻塞其他线程。 - 3. 重新加锁,并设置 DEFER 宏以自动释放,确保无论后续怎么 return,锁都会释放,是一种资源管理策略。
- 4. 健壮性检查:一是 RPC 是否调用成功,二是检查自己还是不是 Leader 和自己的 term 是否被更新过,如果被更新直接返回。
- 5. 如果返回的 follower term 比自己大,那么就将自己的身份转为 Follower,更新自己的 term 并重置选举状态(依旧三变),更新完还要做持久化处理。
- 6. 快照发送成功后更新 leader 对该 follower 维护的状态:
m_matchIndex[server] = args.lastsnapshotincludeindex();m_nextIndex[server] = m_matchIndex[server] + 1;
- Leader 在发现某个 follower 落后太多(即 follower 的
InstallSnapshot():RPC 接口函数,上面的leaderSendSnapShot()
定时器
- Raft 向状态机定时写入:applierTicker()
- 心跳发送定时器:leaderHearBeatTicker()
- 选举超时定时器:electionTimeOutTicker()
这三个定时器需要三个线程,后改成两个协程+一个线程。
main函数
在 example 目录中,启动支持两个命令行参数:
-n:集群节点数-f:Raft 节点配置文件(用于通信地址记录)
示例:./raftCoreRun -n 3 -f test.conf
持久化
即把不能丢失的数据保存到磁盘。
持久化的内容:
- raft节点的部分信息
- m currentTerm:当前节点的 Term,避免重复到一个 Term,可能遇到重复投票等问题。
- m_votedFor:当前 Term 给谁投过票,避免故障后重复投票。
- m_logs:raft 节点保存的全部日志信息。
- kvDb的快照
- m_lastSnapshotlncludelndex:快照的信息,快照最新包含拿过日志 index。
- m_lastSnapshotIncludeTerm:快照的信息,快照最新包含哪个日志 Term,与 m_ lastSnapshotIncludelndex 是对应的。
持久化的原因:
共识安全和优化,除了 snapshot 相关的部分,其他部分都是为了共识安全。
日志一个一个叠加,会导致最后的存储非常大,因此使用 snapshot 来压缩日志。
ps:snapshot 可以压缩日志是因为日志是追加写的,对于一个变量的重复修改可能会重复保存,导致日志存了一些无用的内容,空间不断增大。但理论上只保存一个变量最后那次修改后的值即可,snapshot 是原地写,空间自然就减小了。
持久化的时间节点:
需要持久化的内容发生改变的时候就要注意持久化,比如 term 增加、日志增加等等。
谁负责调用持久化:
谁来调用都可以,只要能保证需要持久化的内容能正确持久化即可。本项目选择的是 raft 类自己来完成持久化,因为 raft 类最方便感知自己的 term 之类的信息有没有变化。
ps:虽然持久化很耗时,但是持久化这些内容的时候不要放开锁,防止其他线程改变了这些值,导致异常。
具体怎么实现持久化:
持久化是一个非常难的事情,因为持久化需要考虑:速度、大小和二进制安全。本项目目前采用的是使用 boost 库中的持久化实现,将需要持久化的数据转化成 std::string 类型再写入到磁盘。
std::string Raft::persistData() {
BoostPersistRaftNode boostPersistRaftNode;
boostPersistRaftNode.m_currentTerm = m_currentTerm;
boostPersistRaftNode.m_votedFor = m_votedFor;
boostPersistRaftNode.m_lastSnapshotIncludeIndex = m_lastSnapshotIncludeIndex;
boostPersistRaftNode.m_lastSnapshotIncludeTerm = m_lastSnapshotIncludeTerm;
for (auto& item : m_logs) {
boostPersistRaftNode.m_logs.push_back(item.SerializeAsString());
}
std::stringstream ss;
boost::archive::text_oarchive oa(ss);
oa << boostPersistRaftNode;
return ss.str();
}
kvServer
相当于是个中间组件,负责沟通 kvDB 和 raft 节点。
kvServer 通过下面两个变量实现与上层的 kvDB 和下层的 raft 节点沟通。
std::shared_ptr<LockQueue<ApplyMsg>> applyChan; // kvServer 和 raft 节点的通信管道
std::unordered_map<std::string, std::string> m_kvDB; // 用unordered map来替代 kv 数据库kvServer 和 raft 类中各持有一个 applyChan,来完成相互的通信。其中 LockQueue 是一个并发的安全队列,这种方式其实是模仿的 golang 中 channel 机制。
kvServer 处理外部请求的步骤:
从下面结构图中可以看出 kvServer 负责与外部的 clerk(客户端)通信,一个外部请求的处理可以简单地看成三步:
- 接收外部请求。
- 本机内部与 raft 和 kvDB 协商如何处理请求。
- 返回外部响应。
其中,第一步和第三步使用个人完成的 RPC 完成。
相关函数:
void PutAppend(google::protobuf::RpcController *controller, const ::raftKVRpcProctoc::PutAppendArgs *request, ::raftKVRpcProctoc::PutAppendReply *response, ::google::protobuf::Closure *done) override;
void Get(google::protobuf::RpcController *controller, const ::raftKVRpcProctoc::GetArgs *request, ::raftKVRpcProctoc::GetReply *response, ::google::protobuf::Closure *done) override;顾名思义,请求分成两种:get 和 put(也就是set)。
如果是 putAppend,clerk 中就调用 PutAppend 的 rpc;如果是 Get,clerk 中就调用 Get 的 rpc。
ps:raftServer 等同于上述的 kvServer
线性一致性
https://segmentfault.com/a/1190000022248118#item-1
强一致性和弱一致性只是一种统称,按照从强到弱,可以划分为
- 线性一致性Linearizability consistency ,也叫原子性
- 顺序一致性 Sequential consistency
- 因果一致性 Causal consistency
- 最终一致性 Eventual consistency
强一致性包括线性一致性和顺序一致性,其他的都是弱一致性。
在强一致性集群中,对任何一个节点发起请求都会得到相同的回复,但将产生相对高的延迟。而弱一致性具有更低的响应延迟,但可能会回复过期的数据,最终一致性就是经过一段时间后终会到达一致的弱一致性。
什么是线性一致性:
线性一致性又被称为强一致性、严格一致性、原子一致性。是程序能实现的最高的一致性模型,也是分布式系统用户最期望的一致性,CAP 中的 C 一般就指它。
顺序一致性中进程只关心大家认同的顺序一样就行,不需要与全局时钟一致,线性就更严格,从这种偏序(partial order)要达到全序(total order)。
要求是:
- 1.任何一次读都能读到某个数据的最近一次写的数据。
- 2.系统中的所有进程,看到的操作顺序,都与全局时钟下的顺序一致。
一个系列的执行历史是一系列的客户请求,或许这是来自多个客户端的多个请求。如果执行历史整体可以按照一个顺序排列,且排列顺序与客户端请求的实际时间相符合,那么它就是线性一致的。当一个客户端发出一个请求,得到一个响应,之后另一个客户端发出一个请求,也得到响应,那么这两个请求之间是有顺序的,因为一个在另一个完成之后才开始。一个线性一致的执行历史中的操作是非并发的,也就是时间上不重合的客户端请求与实际执行时间匹配。并且,每个读操作都看到最近一次写入的值。
简单来说就是,非并发的客户端请求的执行操作,正好按照请求的时间顺序执行,每个操作都可以看到最新的写入,这就是线性一致。如果一个操作在另一个操作开始前就结束了,那么这个操作在执行历史中必须出现在另一个操作前面。
对于一个操作来说,从请求发出到收到回复,是一个时间段。因为操作中包含了很多步骤,至少包含:网络传输 → 数据处理 → 数据真正写入数据库 → 数据处理 → 网络传输。那么操作真正完成(数据真正写入数据库)可以看成是一个时间点,操作真正完成可能发生在操作时间段的任何一个时间点。
raft 是如何做到的:
每个 client 都有一个唯一的标识符 ClientId,它的每个不同命令有一个顺序递增的 Commandld,这两个 ID 可以唯一确定一个不同的命令,从而使得各个 raft 节点可以保存各命令是否已应用以及应用以后的结果。也就是说,对于每个 client,都有一个唯一标识,对于每个 client,只执行递增的命令。
在保证线性一致的情况下如何写 kv:
// 通过超时 pop 来限定命令执行时间,如果超时时间到了还没拿到消息,说明命令执行超时了
if (!chForRaftIndex->timeOutPop(CONSENSUS_TIMEOUT, &raftCommitOp)) { // 超时了
if (ifRequestDuplicate(op.ClientId, op.RequestId)) {
reply->set_err(OK); // 虽然超时了,但因为是重复的请求,所以返回 ok,就算没有超时,在真正执行的时候也要判断是否重复
} else {
reply->set_err(ErrWrongLeader); /// 返回此消息的目的是让 clerk 重新尝试
}
} else { // 没超时,命令可能真正地在 raft 集群成功执行了
if (raftCommitOp.ClientId == op.ClientId && raftCommitOp.RequestId == op.RequestId) {
// 有可能 leader 发生变更导致日志被覆盖,因此必须检查
reply->set_err(OK);
} else {
reply->set_err(ErrWrongLeader);
}
}需要注意的是,这里的命令执行成功指的是本条命令在整个 raft 集群达到同步的状态,而不是一台机器上的 raft 节点保存了该命令。
在保证线性一致的情况下如何读 kv:
if (!chForRaftIndex->timeOutPop(CONSENSUS_TIMEOUT, &raftCommitOp)) { // 超时了
int _ = -1;
bool isLeader = false;
m_raftNode->GetState(&_, &isLeader);
if (ifRequestDuplicate(op.ClientId, op.RequestId) && isLeader) {
// 超时了说明 raft 集群不保证已经 commitIndex 过该日志,但是如果是已经提交过的 get 请求,是可以再执行的,不会违反线性一致性
std::string value;
bool exist = false;
ExecuteGetOpOnKVDB(op, &value, &exist);
if (exist) {
reply->set_err(OK);
reply->set_value(value);
} else {
reply->set_err(ErrNoKey);
reply->set_value("");
}
} else {
reply->set_err(ErrWrongLeader); // 返回该信息的目的是让 clerk 换一个节点重试
}
} else { // 没超时,即 raft 已经提交了该 command,可以正式开始执行了
if (raftCommitOp.ClientId == op.ClientId && raftCommitOp.RequestId == op.RequestId) {
std::string value;
bool exist = false;
ExecuteGetOpOnKVDB(op, &value, &exist);
if (exist) {
reply->set_err(OK);
reply->set_value(value);
} else {
reply->set_err(ErrNoKey);
reply->set_value("");
}
} else {
reply->set_err(ErrWrongLeader);
}
}读与写的不同之处在于,读就算已经操作过了也可以重复执行,不会违反线性一致性,因为毕竟不会改变数据库本身的内容。
下面以 GET 请求,也就是一个读操作为例子看一看流程:
首先是外部 RPC 调用 GET
void KvServer::Get(google::protobuf::RpcController *controller, const ::raftKVRpcProctoc::GetArgs *request, ::raftKVRpcProctoc::GetReply *response, ::google::protobuf::Closure *done) {
KvServer::Get(request, response);
done->Run();
}然后是处理来自 clerk 的 GET RPC,根据请求参数生成 Op,生成 Op 的原因是 raft 和 raftServer(即 kvServer)沟通用的是类似于 go 中的 channel 机制,然后向下执行即可。注意在这个过程中需要判断当前节点是不是 leader,如果不是就返回 ErrWrongLeader,让 clerk 换一个节点尝试。
void KvServer::Get(const raftKVRpcProctoc::GetArgs *args, raftKVRpcProctoc::GetReply *reply) {
Op op;
op.Operation = "Get";
op.Key = args->key();
op.Value = "";
op.ClientId = args->clientid();
op.RequestId = args->requestid();
int raftIndex = -1;
int _ = -1;
bool isLeader = false;
// raftIndex 是 raft 预计的 logIndex,虽然是预计,但在正确情况下是准确的,op 的具体内容对 raft 来说是隔离的
m_raftNode->Start(op, &raftIndex, &_, &isLeader);
if (!isLeader) {
reply->set_err(ErrWrongLeader);
return;
}
// create waitForCh
m_mtx.lock();
if (waitApplyCh.find(raftIndex) == waitApplyCh.end()) {
waitApplyCh.insert(std::make_pair(raftIndex, new LockQueue<Op>()));
}
auto chForRaftIndex = waitApplyCh[raftIndex];
m_mtx.unlock(); // 直接解锁,等待任务执行完成,不能一直拿锁等待
// timeout
Op raftCommitOp;
if (!chForRaftIndex->timeOutPop(CONSENSUS_TIMEOUT, &raftCommitOp)) { // 超时了
// DPrintf("[GET TIMEOUT!!!]From Client %d (Request %d) To Server %d, key %v, raftIndex %d",
// args.ClientId, args.RequestId, kv.me, op.Key, raftIndex)
// todo 2023年06月01日
int _ = -1;
bool isLeader = false;
m_raftNode->GetState(&_, &isLeader);
if (ifRequestDuplicate(op.ClientId, op.RequestId) && isLeader) {
// 超时了说明 raft 集群不保证已经 commitIndex 过该日志,但是如果是已经提交过的 get 请求,是可以再执行的,不会违反线性一致性
std::string value;
bool exist = false;
ExecuteGetOpOnKVDB(op, &value, &exist);
if (exist) {
reply->set_err(OK);
reply->set_value(value);
} else {
reply->set_err(ErrNoKey);
reply->set_value("");
}
} else {
reply->set_err(ErrWrongLeader); // 返回该信息的目的是让 clerk 换一个节点重试
}
} else {
// 没超时,即 raft 已经提交了该 command,可以正式开始执行了
// DPrintf("[WaitChanGetRaftApplyMessage<--]Server %d , get Command <-- Index:%d , ClientId %d,
// RequestId %d, Opreation %v, Key :%v, Value :%v", kv.me, raftIndex, op.ClientId, op.RequestId,
// op.Operation, op.Key, op.Value)
// todo 这里还要再次检验的原因:感觉不用检验,因为leader只要正确的提交了,那么这些肯定是符合的
if (raftCommitOp.ClientId == op.ClientId && raftCommitOp.RequestId == op.RequestId) {
std::string value;
bool exist = false;
ExecuteGetOpOnKVDB(op, &value, &exist);
if (exist) {
reply->set_err(OK);
reply->set_value(value);
} else {
reply->set_err(ErrNoKey);
reply->set_value("");
}
} else {
reply->set_err(ErrWrongLeader);
// DPrintf("[GET ] 不满足:raftCommitOp.ClientId{%v} == op.ClientId{%v} &&
// raftCommitOp.RequestId{%v}
// == op.RequestId{%v}", raftCommitOp.ClientId, op.ClientId, raftCommitOp.RequestId,
// op.RequestId)
}
}
m_mtx.lock();
auto tmp = waitApplyCh[raftIndex];
waitApplyCh.erase(raftIndex);
delete tmp;
m_mtx.unlock();
}RPC 如何实现调用
以 Raft 类举例,通过写 .proto 文件,用 protoc 编译器自动生成 RPC 服务基类。
继承生成的类,重写 RPC 方法即可。
public: // 重写基类方法,因为 RPC 远程调用真正调用的是这些方法
// 序列化,反序列化等操作 RPC 框架都已经做完了,因此这里只需要获取值然后真正调用本地方法即可
void AppendEntries(google::protobuf::RpcController *controller,
const ::raftRpcProctoc::AppendEntriesArgs *request,
::raftRpcProctoc::AppendEntriesReply *response,
::google::protobuf::Closure *done) override;
void InstallSnapshot(google::protobuf::RpcController *controller,
const ::raftRpcProctoc::InstallSnapshotRequest *request,
::raftRpcProctoc::InstallSnapshotResponse *response,
::google::protobuf::Closure *done) override;
void RequestVote(google::protobuf::RpcController *controller,
const ::raftRpcProctoc::RequestVoteArgs *request,
::raftRpcProctoc::RequestVoteReply *response,
::google::protobuf::Closure *done) override;重写函数中的四个参数:
google::protobuf::RpcController *controller- 作用:控制 RPC 调用的上下文信息
- 可以用它来:取消调用、获取错误信息、设置失败状态
- 常用场景:检查网络状态,检测客户端是否取消调用
const ::raftRpcProctoc::AppendEntriesArgs *request- 这是客户端传来的请求参数,包含 Raft 的请求数据
::raftRpcProctoc::AppendEntriesReply *response- 需要填充这个响应对象,然后返回给客户端。内容一般包括:当前节点的任期(如果发现自己任期比客户端大)、是否接受了日志条目(
success字段)
- 需要填充这个响应对象,然后返回给客户端。内容一般包括:当前节点的任期(如果发现自己任期比客户端大)、是否接受了日志条目(
::google::protobuf::Closure *done- 这是一个回调函数指针,表示“我处理完了,可以返回结果了”。必须在函数末尾调用
done->Run();如果忘记调用它,RPC 框架那边会一直“挂起”,不会向客户端返回响应。
- 这是一个回调函数指针,表示“我处理完了,可以返回结果了”。必须在函数末尾调用
Clerk 客户端
clerk 相当于是一个外部的客户端,作用就是向整个 raft 集群发起命令并接收响应。在 kvServer 一节中有提到过,clerk 与 kvServer 需要建立网络连接,既然我们实现了一个简单的 RPC,那么我们不妨使用 RPC 来完成这个过程。clerk 本身还是比较简单的,唯一要注意的就是如果 RPC 返回对端不是 leader 的话,就需要再调用另一个节点重试,直到成功与 leader 建立连接,从而保证请求能够被正确处理和复制,确保线性一致性。
int main() {
Clerk client; // 创建一个 Clerk 客户端实例
client.Init("test.conf"); // 初始化客户端,传入配置文件
auto start = now();
int count = 500; // 备进行 500 次写+读测试
int tmp = count;
while (tmp--) {
client.Put("x", std::to_string(tmp)); // 每次循环,把变量 tmp 转为字符串,写入 key "x"
std::string get1 = client.Get("x"); // 紧跟着每次写入后,马上读取同一个 key "x"
std::printf("get return :{%s}\r\n", get1.c_str());
}
return 0;
}上述代码很简单,重点关注下面的 Init 函数。这个函数会读取参数中配置文件所列出的所有 Raft 节点的 IP 和 Port,然后为每个节点创建一个 raftServerRpcUtil 实例并保存到 m_servers,从而建立客户端到各节点的 RPC 通道。
// 初始化客户端
void Clerk::Init(std::string configFileName) {
// 获取所有 raft 节点的 ip 和 port 并进行连接
MprpcConfig config; // MprpcConfig 是自研 MprRpc 框架的配置解析器
config.LoadConfigFile(configFileName.c_str()); // 解析配置文件(配置文件里就是各节点的 IP 和端口)
// 构造节点列表
std::vector<std::pair<std::string, short>> ipPortVt;
for (int i = 0; i < INT_MAX - 1; ++i) {
std::string node = "node" + std::to_string(i);
std::string nodeIp = config.Load(node + "ip");
std::string nodePortStr = config.Load(node + "port");
if (nodeIp.empty()) {
break;
}
ipPortVt.emplace_back(nodeIp, atoi(nodePortStr.c_str()));
}
// 为每个节点建立 RPC 通道对象
for (const auto& item : ipPortVt) {
std::string ip = item.first;
short port = item.second;
auto* rpc = new raftServerRpcUtil(ip, port);
m_servers.push_back(std::shared_ptr<raftServerRpcUtil>(rpc));
}
}再关注一下 client.Put("x", std::to_string(tmp)); 这句代码中的 put 函数,put 函数实际上调用的是 PutAppend 函数。
void Clerk::Put(std::string key, std::string value) { PutAppend(key, value, "Put"); }
void Clerk::PutAppend(std::string key, std::string value, std::string op) {
// 向集群写入一条 PutAppend 指令,内部循环重试,直到由当前 Leader 成功提交
m_requestId++; // 为本次操作生成单调递增的全局请求号
auto requestId = m_requestId; // 幂等保证auto requestId = m_requestId; // 幂等保证,Leader 收到 (clientId, requestId) 时,如已处理过会直接返回 OK,不会再次插入日志
auto server = m_recentLeaderId; // 先从“最近认为的 Leader” 开始试
while (true) { // 无限重试,直到 Leader 提交该指令
// 构造 RPC 请求
raftKVRpcProctoc::PutAppendArgs args;
args.set_key(key);
args.set_value(value);
args.set_op(op);
args.set_clientid(m_clientId);
args.set_requestid(requestId);
raftKVRpcProctoc::PutAppendReply reply; // 创建准备接收的响应
bool ok = m_servers[server]->PutAppend(&args, &reply); // 发送 RPC
if (!ok || reply.err() == ErrWrongLeader) { // 如果调用失败或发给了 Follower
DPrintf("【Clerk::PutAppend】原以为的leader:{%d}请求失败,向新leader{%d}重试 ,操作:{%s}", server,
server + 1, op.c_str());
if (!ok) {
DPrintf("重试原因 ,rpc失敗 ,");
}
if (reply.err() == ErrWrongLeader) {
DPrintf("重試原因:非leader");
}
server = (server + 1) % m_servers.size(); // 轮询下一个节点
continue; // 继续 while(true)
}
if (reply.err() == OK) { // 即真正的 Leader 已成功提交
m_recentLeaderId = server; // 记住新 Leader,下次优先发给它
return;
}
}
}上层 KV 数据库
数据结构
原项目是使用 unordered_map 来代替上层的 kvDB,我们对其进行优化,使用跳表。在以下几个方面带来了性能和功能的提升:
- 有序性
unordered_map是哈希结构,不保持键的任何顺序。- 跳表本质是多级链表,天然按键有序。
- 单点操作时间复杂度
unordered_map:在负载因子稳定、冲突均匀时为 O(1),但会受重哈希与冲突的影响,极端值可退化到 O(n);跳表始终为 O(log n),更平滑。
- 扩容
unordered_map扩容时需要重新哈希,带来性能损耗。

为什么不用 map(红黑树)来实现?
- 从内存占用上来比较,跳表比平衡树(包括红黑树、AVL 树)更灵活一些。平衡树每个节点包含两个指针(分别指向左右子树),而跳表每个节点包含的指针数目平均为 1/(1-p),具体取决于参数 p 的大小(p 是在构建或插入节点时,决定该节点是否拥有更高一层指针的概率)。如果像 Redis 里的实现一样,取 p=1/4,那么平均每个节点包含 1.33 个指针,比平衡树更有优势。但我们的 p 取 0.5,那么每个节点平均有 2 个指针,和平衡树一样了。
- 在做范围查找的时候,跳表比平衡树操作要简单。在平衡树上,我们找到指定范围的小值之后,还需要以中序遍历的顺序继续寻找其它不超过大值的节点。如果不对平衡树进行一定的改造,这里的中序遍历并不容易实现。而在跳表上进行范围查找就非常简单,只需要在找到小值之后,对第1层链表进行若干步的遍历就可以实现。
- 从算法实现难度上来比较,跳表比平衡树要简单得多。平衡树的插入和删除操作可能引发子树的调整逻辑复杂,而跳表的插入和删除只需要修改相邻节点的指针,操作简单又快速。
总结
- 如果与 unordered_map(哈希表)比的话,跳表的优势在于:
unordered_map是哈希结构,不保持键的有序性,而跳表本质是多级链表,天然按键有序。unordered_map在负载因子稳定、冲突均匀时为 O(1),但会受重哈希与冲突的影响,极端值可退化到 O(n),而跳表始终为 O(log n),更平滑。
- 如果与 map(红黑树)比的话,跳表的优势在于:
- 从算法实现难度上来比较,跳表比平衡树要简单得多。
- 平衡树的插入和删除操作可能引发子树的调整逻辑复杂,而跳表的插入和删除只需要修改相邻节点的指针,操作简单又快速。
- 从内存占用上来比较,平衡树每个节点包含两个指针,而跳表平均每个节点包含 1.33 个指针(若取 p=1/4),比平衡树更有优势。
核心代码
Node 类模板
template<typename K, typename V>
class Node {
public:
Node() {}
Node(K k, V v, int);
~Node();
K get_key() const;
V get_value() const;
void set_value(V);
Node<K, V> **forward; // Node<K, V> ** 表示一个指针,它指向的是一个存储 Node<K, V> * 类型指针的数组
int node_level;
private:
K key;
V value;
};
Node类表示跳表中的节点,每个节点包含一个键key、一个值value、一个节点层级node_level和一个指向不同层级下一个节点的指针数组forward。- 提供了构造函数、析构函数、获取键和值的方法以及设置值的方法。
Node 类成员函数实现
template<typename K, typename V>
Node<K, V>::Node(const K k, const V v, int level) {
this->key = k;
this->value = v;
this->node_level = level;
this->forward = new Node<K, V>*[level+1];
memset(this->forward, 0, sizeof(Node<K, V>*)*(level+1));
};
template<typename K, typename V>
Node<K, V>::~Node() {
delete []forward;
};
template<typename K, typename V>
K Node<K, V>::get_key() const {
return key;
};
template<typename K, typename V>
V Node<K, V>::get_value() const {
return value;
};
template<typename K, typename V>
void Node<K, V>::set_value(V value) {
this->value=value;
};
- 构造函数初始化节点的键、值和层级,并为
forward数组分配内存。 - 析构函数释放
forward数组的内存。 get_key和get_value方法分别返回节点的键和值。set_value方法设置节点的值。
SkipList 类模板
template <typename K, typename V>
class SkipList {
public:
SkipList(int);
~SkipList();
int get_random_level();
Node<K, V>* create_node(K, V, int);
int insert_element(K, V);
void display_list();
bool search_element(K);
void delete_element(K);
void dump_file();
void load_file();
void clear(Node<K,V>*);
int size();
private:
void get_key_value_from_string(const std::string& str, std::string* key, std::string* value);
bool is_valid_string(const std::string& str);
private:
int _max_level;
int _skip_list_level;
Node<K, V> *_header;
std::ofstream _file_writer;
std::ifstream _file_reader;
int _element_count;
};
SkipList类表示跳表数据结构,包含以下成员:- 最大层级
_max_level和当前层级_skip_list_level(层级索引是[0,_skip_list_level])。 - 头节点指针
_header。 - 文件写入流
_file_writer和文件读取流_file_reader。 - 当前元素数量
_element_count。
- 最大层级
- 提供了插入、删除、查找、显示、数据落盘和加载等公共方法,以及一些辅助的私有方法(详见下方)。
SkipList 类成员函数实现
1 构造函数和析构函数
template <typename K, typename V>
SkipList<K, V>::SkipList(int max_level)
{
this->_max_level = max_level;
this->_skip_list_level = 0;
this->_element_count = 0;
// create header node and initialize key and value to null
K k;
V v;
this->_header = new Node<K, V>(k, v, _max_level);
};
template <typename K, typename V>
SkipList<K, V>::~SkipList()
{
if (_file_writer.is_open())
{
_file_writer.close();
}
if (_file_reader.is_open())
{
_file_reader.close();
}
// 递归删除跳表链条
if (_header->forward[0] != nullptr)
{
clear(_header->forward[0]);
}
delete (_header);
}
- 构造函数初始化跳表的最大层级、当前层级和元素数量,并创建头节点。
- 析构函数关闭文件流,递归删除跳表中的所有节点,最后删除头节点。
2 创建节点和随机层级
template<typename K, typename V>
Node<K, V>* SkipList<K, V>::create_node(const K k, const V v, int level) {
Node<K, V> *n = new Node<K, V>(k, v, level);
return n;
}
template<typename K, typename V>
int SkipList<K, V>::get_random_level() {
int k = 1;
while (rand() % 2) {
k++;
}
k = (k < _max_level) ? k : _max_level;
return k;
}create_node方法创建一个新的节点。get_random_level方法随机生成一个节点的层级。
3 ※插入元素
template <typename K, typename V>
int SkipList<K, V>::insert_element(const K key, const V value)
{
mtx.lock(); // 全局互斥,保证线程安全
Node<K, V> *current = this->_header; // 从头结点开始
Node<K, V> *update[_max_level + 1]; // update[i] 最终将指向 第 i 层 插入位置前的节点,即前驱节点
memset(update, 0, sizeof(Node<K, V> *) * (_max_level + 1));
// 自顶向下查找插入位置,找到每一层的插入位置的前驱节点
for (int i = _skip_list_level; i >= 0; i--)
{
while (current->forward[i] != NULL && current->forward[i]->get_key() < key)
{
current = current->forward[i]; // 水平向右找
}
update[i] = current; // 记录前一个节点
}
// 移到最底层,检查是否已经有重复元素,因为最底层包含全部元素
current = current->forward[0]; // 最终 current 指向底层首个 ≥ key 的节点
// 如果已经有相同 key,不允许插入重复键,直接返回1
if (current != NULL && current->get_key() == key)
{
std::cout << "key: " << key << ", exists" << std::endl;
mtx.unlock();
return 1;
}
// 如果 current 为 NULL,则表示已到达层级末尾
// 如果 current 的 key 不等于 key,则表示必须在 update[0] 和当前节点之间插入节点
if (current == NULL || current->get_key() != key)
{
int random_level = get_random_level(); // 生成随机层级,二分之一的几率递增一层
// 如果生成的随机层级大于跳表的层级,则跳表需要“长高”
if (random_level > _skip_list_level)
{
for (int i = _skip_list_level + 1; i < random_level + 1; i++)
{
update[i] = _header; // 新层级使用头节点作为前驱
}
_skip_list_level = random_level;
}
// 在这层上创建并链接新节点
Node<K, V> *inserted_node = create_node(key, value, random_level);
for (int i = 0; i <= random_level; i++)
{
inserted_node->forward[i] = update[i]->forward[i]; // 将前驱节点的下一个节点作为新节点的后继节点
update[i]->forward[i] = inserted_node; // 前驱节点的下一个节点变成了新插入的节点
}
std::cout << "Successfully inserted key:" << key << ", value:" << value << std::endl;
_element_count++;
}
mtx.unlock(); // 解锁
return 0;
}- 插入元素时,首先使用互斥锁保护临界区。
- 从最高层级开始查找插入位置,记录每个层级插入元素的前驱节点。
- 检查最底层,如果键已经存在,输出提示信息并返回 1。
- 否则,随机生成一个层级值,创建新节点并插入到相应位置,更新 update 和 forward 数组以及元素数量,最后释放互斥锁并返回 0。
4 删除元素
template <typename K, typename V>
void SkipList<K, V>::delete_element(K key)
{
mtx.lock(); // 加锁
Node<K, V> *current = this->_header; // 从头节点开始
Node<K, V> *update[_max_level + 1]; // 保存第 i 层 中待删节点的前驱
memset(update, 0, sizeof(Node<K, V> *) * (_max_level + 1));
// 搜索逻辑与插入相同:自顶向下、右移后下跳
for (int i = _skip_list_level; i >= 0; i--)
{
while (current->forward[i] != NULL && current->forward[i]->get_key() < key)
{
current = current->forward[i];
}
update[i] = current; // 记录前驱
}
current = current->forward[0]; // 最终 current 指向底层首个 ≥ key 的节点
if (current != NULL && current->get_key() == key)
{
// 从底层开始删除每一层级的目标节点
for (int i = 0; i <= _skip_list_level; i++)
{
// 一旦某层前驱的下一个节点并不指向目标节点,说明目标节点在那层不存在,直接 break(因为更高层肯定也没有)
if (update[i]->forward[i] != current) break;
// 使得前驱的下一个节点变成目标节点的下一个节点,即断开目标节点的链接,跳过目标节点
update[i]->forward[i] = current->forward[i];
}
// 删除元素后可能导致顶层没有元素了,需要删除顶层
while (_skip_list_level > 0 && _header->forward[_skip_list_level] == 0)
{
_skip_list_level--;
}
std::cout << "Successfully deleted key " << key << std::endl;
delete current; // 释放内存
_element_count--;
}
mtx.unlock(); // 解锁
return;
}- 删除元素时,首先使用互斥锁保护临界区。
- 从最高层级开始查找要删除的节点,记录每个层级待删除元素的前驱节点。
- 如果找到要删除的节点,将其从每个层级中断链,如果最高层没元素了,则需要删除最高层,更新层级和元素数量。
- 最后物理释放删除节点,释放互斥锁。
5 查找元素
template <typename K, typename V>
bool SkipList<K, V>::search_element(K key)
{
std::cout << "search_element-----------------" << std::endl;
Node<K, V> *current = _header;
// 从最高层开始找
for (int i = _skip_list_level; i >= 0; i--)
{
while (current->forward[i] && current->forward[i]->get_key() < key)
{
// 在当前层里,只要下一个节点 key < 目标 key 就右移,相当于在层 i 上一次性跨越若干节点,直到即将超越目标
// 到了下一层时,current 已经定位在最接近目标且不超过它的节点,继续下探
current = current->forward[i];
}
}
// 到达底层并将指针推进到我们之前定位的下一个节点
current = current->forward[0];
// 如果这个节点就是我们要的
if (current and current->get_key() == key)
{
std::cout << "Found key: " << key << ", value: " << current->get_value() << std::endl;
return true;
}
std::cout << "Not Found Key:" << key << std::endl;
return false;
}- 从最高层级开始查找要查找的节点,找到则输出信息并返回
true,否则输出信息并返回false。
6 数据落盘
template <typename K, typename V>
void SkipList<K, V>::dump_file()
{
std::cout << "dump_file-----------------" << std::endl;
_file_writer.open(STORE_FILE);
Node<K, V> *node = this->_header->forward[0];
while (node != NULL)
{
_file_writer << node->get_key() << ":" << node->get_value() << "\n";
std::cout << node->get_key() << ":" << node->get_value() << ";\n";
node = node->forward[0];
}
_file_writer.flush();
_file_writer.close();
return;
}- 打开存储文件,将跳表中的所有节点的键和值写入文件,最后关闭文件。
7 加载数据
- 打开存储文件,逐行读取文件内容,解析出键和值,插入到跳表中,最后关闭文件。
8 解析字符串
get_key_value_from_string方法从字符串中解析出键和值。is_valid_string方法检查字符串是否包含分隔符,是否为空。
9 显示跳表
- 遍历每个层级,输出该层级的所有节点的键和值。
10 获取跳表大小
- 返回跳表中当前元素的数量。
将跳表植入本项目
1 修改 dump_file 和 load_file 接口
上述跳表中的这两个方法逻辑是直接落盘和从文件中读取数据,以落盘方法举例,关键代码如下:
while (node != NULL)
{
_file_writer << node->get_key() << ":" << node->get_value() << "\n";
std::cout << node->get_key() << ":" << node->get_value() << ";\n";
node = node->forward[0];
}其中 _file_writer 的定义是 std::ofstream _file_writer, 代码逻辑为在遍历的过程中不断将数据写入到磁盘,使用 : 和 \n 作为分隔符。
那么这里就存在数据不安全的问题,即 key 和 value 中如果已经存在 : 或 \n 字符,程序可能会发生异常。为了数据安全,这里采用的方法依旧是使用 boost 的序列化库。新增 SkipListDump 类,目的就是实现安全的序列化和反序列化。其定义也很简单,与 raft 和 kvServer 中的序列化方式相同,也是 boost 库序列化的最简单的方式:
template <typename K, typename V>
class SkipListDump {
public:
friend class boost::serialization::access;
template <class Archive>
void serialize(Archive &ar, const unsigned int version) {
ar & keyDumpVt_;
ar & valDumpVt_;
}
std::vector<K> keyDumpVt_;
std::vector<V> valDumpVt_;
public:
void insert(const Node<K, V> &node);
};template <typename K, typename V>
void SkipListDump<K, V>::insert(const Node<K, V> &node) {
keyDumpVt_.emplace_back(node.get_key());
valDumpVt_.emplace_back(node.get_value());
}那么改造后的落盘方法如下:
template <typename K, typename V>
std::string SkipList<K, V>::dump_file() {
Node<K, V> *node = this->_header->forward[0];
SkipListDump<K, V> dumper;
while (node != nullptr) {
dumper.insert(*node);
node = node->forward[0];
}
std::stringstream ss;
boost::archive::text_oarchive oa(ss);
oa << dumper;
return ss.str();
}2 新增 insert_set_element 接口
增加的原因是为了配合下层 kvServer 的 set 方法,如果 key 不存在就增加这个 key,如果 key 已经存在就将 value 修改成新值。这个作用与 insert_element 方法类似,但它只能插入新元素,存在相同 key 不会进行修改。
template <typename K, typename V>
void SkipList<K, V>::insert_set_element(K &key, V &value) {
V oldValue;
if (search_element(key, oldValue)) {
delete_element(key);
}
insert_element(key, value);
}注意 insert_set_element 方法在实现修改元素功能时不能直接找到这个节点,然后修改其值,因为后续可能会有类似“排序”这样的拓展功能,因此目前的实现思路是先删除旧节点,然后再重新插入,达到修改 value 的效果。
两类序列化
1. RPC 场景中使用 protobuf
- RPC(远程过程调用)要求跨进程甚至跨主机通信;
- 需要高效、平台无关的序列化方式;
- protobuf 是 Google 开源的跨语言、高性能序列化协议,非常适合 RPC。
2. 跳表(SkipList)中使用 Boost.Serialization
- Boost.Serialization 是 C++ 的通用序列化库,使用方便;
- 适合本地持久化,比如把跳表写入磁盘或文件;
- 不依赖于跨平台或多语言使用场景。
RPC
Raft 算法中服务器节点之间使用 RPC 进行通信,并且 Raft 中只有两种主要的 RPC:
- RequestVote RPC(请求投票):由 candidate 在选举期间发起。
- AppendEntries RPC(追加条目):由 leader 发起,用来复制日志和提供一种心跳机制。
服务器之间通信的时候会交换当前任期号:
- 如果一个服务器上的当前任期号比其他的小,该服务器会将自己的任期号更新为较大的那个值。
- 如果一个 candidate 或者 leader 发现自己的任期号过期了,它会立即回到 follower 状态。
- 如果一个节点接收到一个包含过期的任期号的请求,它会直接拒绝这个请求。
本项目使用的 RPC 高度依赖于 portobuf,rpcheader.proto 文件如下:
syntax = "proto3";
package RPC;
message RpcHeader
{
bytes service_name = 1;
bytes method_name = 2;
uint32 args_size = 3; // 虽然是 uint32,但 protobuf 编码的时候默认就是变长编码
}由 rpcheader.proto 文件执行命令 protoc --cpp_out=. rpcheader.proto 后,会自动生成如下两个文件:
rpcheader.pb.h:包含结构体类声明、序列化/反序列化接口等。rpcheader.pb.cpp:包含.h中声明的类的定义、序列化逻辑等。
RPC(Remote Procedure Call,远程过程调用)是一种在分布式系统中,让不同模块之间实现透明远程调用的技术。借助 RPC,开发者能够更便捷地构建分布式系统,无需过度关注复杂的底层通信细节 ,调用另一台机器上的方法就如同调用本地方法一样。在分布式系统的设计中,无论系统对外呈现何种表现形式,只要涉及多个主机间的交互协作,网络通讯都是其中不可或缺的关键环节。RPC 技术正是通过对网络通讯进行封装和优化,实现了跨主机方法调用的高效与便捷。
一次 RPC 流程如下图所示:
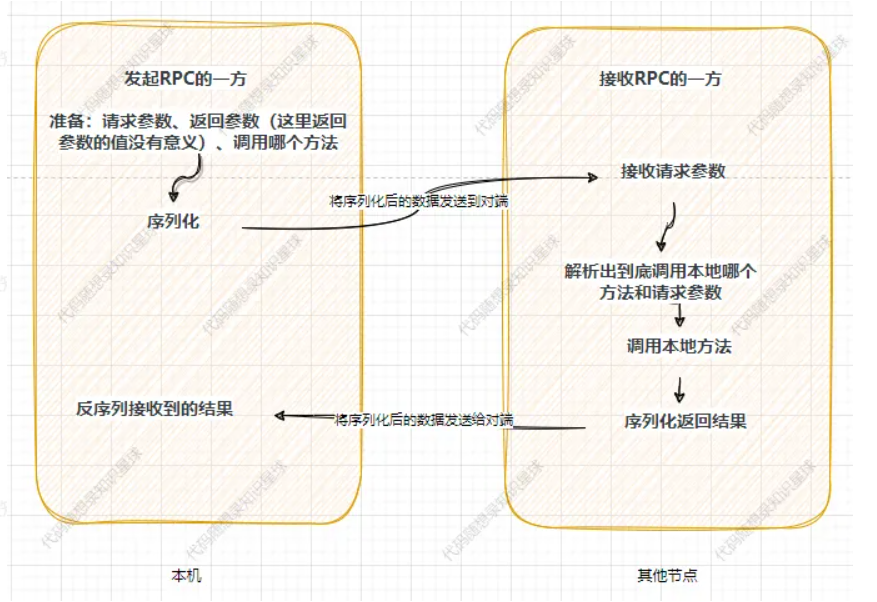
首先,“准备”这一步需要发起者自己完成,示例代码如下:
// stub 是客户端使用的代理对象,相当于把远程的方法本地化了
fixbug::FiendServiceRpc_Stub stub(
new MprpcChannel(ip, port, true)); // 注册进自己实现的 channel 类,channel 类用于自定义发送格式和负责序列化等操作
// rpc 方法的请求参数
fixbug::GetFriendsListRequest request;
request.set_userid(1000);
// rpc 方法的响应
fixbug::GetFriendsListResponse response;
// controller 用来监控一次 RPC 调用是否失败(比如网络断了)
MprpcController controller;
···
// 发起 rpc 方法的调用,实际内部会调用 channel 的 call_method 方法,该方法集中来做所有 rpc 调用的参数序列化和网络发送功能
stub.GetFriendsList(&controller, &request, &response, nullptr);
GetFriendsList()代码如下:
void FiendServiceRpc_Stub::GetFriendsList(::PROTOBUF_NAMESPACE_ID::RpcController* controller,
const ::fixbug::GetFriendsListRequest* request,
::fixbug::GetFriendsListResponse* response,
::google::protobuf::Closure* done) {
channel_->CallMethod(descriptor()->method(0), controller, request, response, done);
}可以看到实际是调用了 channel_->CallMethod 方法,只是第一个参数变成了 descriptor()->method(0),其他参数都是我们在 GetFriendsList() 中传进去的参数,而这个 descriptor()->method(0) 的作用就是表明我们到底是调用的是哪个具体的方法(比如 get、put 等等)。
到这里远端调用需要的东西就齐全了:具体方法、请求参数、响应参数。
另外,在最开始生成 stub 的代码是:
fixbug::FiendServiceRpc_Stub stub(new MprpcChannel(ip, port, true));
其实 GetFriendsList() 中的 channel_ 本质上就是我们自己实现的 MprpcChannel 类,而 channel_->CallMethod 本质上就是调用的 MprpChannel 类的 CallMethod 方法。
那我们看下这个 CallMethod 方法,代码如下:
/**
* header_size + header(service_name method_name args_size) + args
* 所有通过 stub 代理对象调用的 rpc 方法,都会到这里统一通过 rpcChannel 来调用方法,统一做数据序列化和网络发送
*/
void MprpcChannel::CallMethod(const google::protobuf::MethodDescriptor* method,
google::protobuf::RpcController* controller, const google::protobuf::Message* request,
google::protobuf::Message* response, google::protobuf::Closure* done) {
// 如果之前连接断了(文件描述符为 -1),就尝试重新建立 TCP 连接,失败时设置 controller 的错误信息并返回
if (m_clientFd == -1) {
std::string errMsg;
bool rt = newConnect(m_ip.c_str(), m_port, &errMsg);
if (!rt) {
DPrintf("[func-MprpcChannel::CallMethod]重连接ip:{%s} port{%d}失败", m_ip.c_str(), m_port);
controller->SetFailed(errMsg);
return;
} else {
DPrintf("[func-MprpcChannel::CallMethod]连接ip:{%s} port{%d}成功", m_ip.c_str(), m_port);
}
}
// 通过 MethodDescriptor* 中的 ServiceDescriptor* 获取要调用的服务名和方法名
const google::protobuf::ServiceDescriptor* sd = method->service();
std::string service_name = sd->name(); // service_name
std::string method_name = method->name(); // method_name
// 将 protobuf 类型的请求对象 request 序列化成字符串,得到其大小 args_size 用于 header 填写
uint32_t args_size{};
std::string args_str;
if (request->SerializeToString(&args_str)) {
args_size = args_str.size();
} else {
controller->SetFailed("serialize request error!");
return;
}
// 构造自定义 RpcHeader 头部
// 自定义的 RpcHeader 是在自己框架中定义的一个 protobuf 类型,用来描述一次调用元信息,包括:服务名、方法名、参数长度
RPC::RpcHeader rpcHeader;
rpcHeader.set_service_name(service_name);
rpcHeader.set_method_name(method_name);
rpcHeader.set_args_size(args_size);
// 将 RpcHeader 序列化
std::string rpc_header_str;
if (!rpcHeader.SerializeToString(&rpc_header_str)) {
controller->SetFailed("serialize rpc header error!");
return;
}
// 使用 protobuf 的 CodedOutputStream 来构建发送的数据流
std::string send_rpc_str; // 用来保存最终发送的数据
{
// 创建一个 StringOutputStream 用于写入 send_rpc_str
google::protobuf::io::StringOutputStream string_output(&send_rpc_str);
google::protobuf::io::CodedOutputStream coded_output(&string_output);
// 先写入 header 的长度(变长编码)
coded_output.WriteVarint32(static_cast<uint32_t>(rpc_header_str.size()));
// 然后写入 rpc_header 本身
coded_output.WriteString(rpc_header_str);
}
// 最后把参数内容拼接到发送数据末尾
send_rpc_str += args_str;
// 最终格式:header_size + header(service_name method_name args_size) + args
// 使用 send 函数循环发送 RPC 请求
// 如果 send 失败,说明连接可能断了,就关闭旧连接并重连,然后重发,如果还是失败,直接 return
while (-1 == send(m_clientFd, send_rpc_str.c_str(), send_rpc_str.size(), 0)) {
char errtxt[512] = {0};
sprintf(errtxt, "send error! errno:%d", errno);
std::cout << "尝试重新连接,对方ip:" << m_ip << " 对方端口" << m_port << std::endl;
close(m_clientFd);
m_clientFd = -1;
std::string errMsg;
bool rt = newConnect(m_ip.c_str(), m_port, &errMsg);
if (!rt) {
controller->SetFailed(errMsg);
return;
}
}
// 从时间节点来说,这里将请求发送过去之后,RPC 服务的提供者就会开始处理,接收响应的时候就代表已经返回响应了
// 接收 RPC 请求的响应结果,缓存在 recv_buf 中
char recv_buf[1024] = {0};
int recv_size = 0;
if (-1 == (recv_size = recv(m_clientFd, recv_buf, 1024, 0))) {
close(m_clientFd);
m_clientFd = -1;
char errtxt[512] = {0};
sprintf(errtxt, "recv error! errno:%d", errno);
controller->SetFailed(errtxt);
return;
}
// 反序列化 RPC 调用的响应结果,把 server 返回的数据反序列化填入调用者提供的 response 对象
// 使用 ParseFromArray(而非 ParseFromString)是为了避免 \0 截断问题
if (!response->ParseFromArray(recv_buf, recv_size)) {
char errtxt[1050] = {0};
sprintf(errtxt, "parse error! response_str:%s", recv_buf);
controller->SetFailed(errtxt);
return;
}
}
即按照 header_size + header(service_name method_name args_size) + args 的格式将发送内容序列化,然后通过 send 函数循环发送,最后接收响应数据。注意:序列化为二进制数据,只不过用 string 储存,因为 std::string 在 C++ 中不仅是文本容器,也是一个方便的字节缓冲区。
通过上面的步骤,所有的报文都已发送到了对端,即接收 RPC 的一方,那么此时在对端进行下图所示步骤:
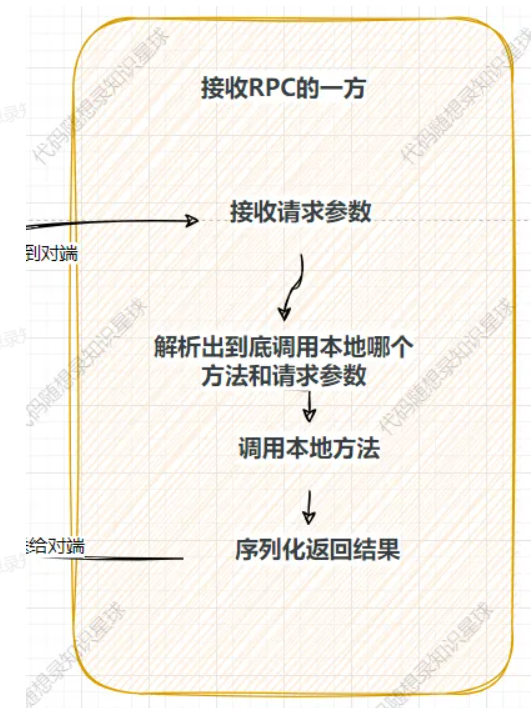
这一系列步骤的主要发生在函数 RpcProvider::OnMessage 中,整个流程可以概括为:
接收请求 → 解析数据 → 查找服务与方法 → 反序列化参数 → 调用业务方法 → 异步返回结果
整体数据结构:
[4字节 header_size][rpc_header(protobuf)][args 参数部分(protobuf)]rpc_header 本身是个 protobuf 消息,内容是:
- service_name
- method_name
- args_size
代码如下:
// 如果远程有一个 RPC 服务的调用请求,那么 OnMessage 方法就会响应
// 因此本函数的作用是:解析请求,然后根据服务名、方法名和参数,来调用 service 的 callmethod 来调用本地的业务
void RpcProvider::OnMessage(const muduo::net::TcpConnectionPtr &conn, muduo::net::Buffer *buffer, muduo::Timestamp) {
// 从网络缓冲区读取所有数据,包含:header_size + rpc_header + args
std::string recv_buf = buffer->retrieveAllAsString();
// 使用 protobuf 的 CodedInputStream 来解析数据流
google::protobuf::io::ArrayInputStream array_input(recv_buf.data(), recv_buf.size());
google::protobuf::io::CodedInputStream coded_input(&array_input);
uint32_t header_size{};
coded_input.ReadVarint32(&header_size); // 解析出 header_size
// 根据 header_size 读取数据头部的原始字节流,反序列化数据,得到 RPC 请求的详细信息
std::string rpc_header_str;
RPC::RpcHeader rpcHeader;
std::string service_name;
std::string method_name;
// 设置读取限制,不必担心数据读多
google::protobuf::io::CodedInputStream::Limit msg_limit = coded_input.PushLimit(header_size);
coded_input.ReadString(&rpc_header_str, header_size); // 解析出 header
// 恢复之前的限制,以便安全地继续读取其他数据
coded_input.PopLimit(msg_limit);
uint32_t args_size{};
// 对数据头部进行反序列化,得到 service_name、method_name、args_size
if (rpcHeader.ParseFromString(rpc_header_str)) {
service_name = rpcHeader.service_name();
method_name = rpcHeader.method_name();
args_size = rpcHeader.args_size();
} else {
// 反序列化失败
std::cout << "rpc_header_str:" << rpc_header_str << " parse error!" << std::endl;
return;
}
// 解析调用方法所需要的实际参数部分 args
std::string args_str; // 获取 RPC 方法参数的字符流数据
// 直接读取 args_size 长度的字符串数据
bool read_args_success = coded_input.ReadString(&args_str, args_size);
// 处理错误:参数数据读取失败
if (!read_args_success) {
return;
}
// 打印调试信息
// std::cout << "============================================" << std::endl;
// std::cout << "header_size: " << header_size << std::endl;
// std::cout << "rpc_header_str: " << rpc_header_str << std::endl;
// std::cout << "service_name: " << service_name << std::endl;
// std::cout << "method_name: " << method_name << std::endl;
// std::cout << "args_str: " << args_str << std::endl;
// std::cout << "============================================" << std::endl;
// 查找服务与方法
// 框架预先注册了本地服务,这里查找出对应的方法对象
auto it = m_serviceMap.find(service_name);
if (it == m_serviceMap.end()) {
std::cout << "服务:" << service_name << " is not exist!" << std::endl;
std::cout << "当前已经有的服务列表为:";
for (auto item : m_serviceMap) {
std::cout << item.first << " ";
}
std::cout << std::endl;
return;
}
auto mit = it->second.m_methodMap.find(method_name);
if (mit == it->second.m_methodMap.end()) {
std::cout << service_name << ":" << method_name << " is not exist!" << std::endl;
return;
}
google::protobuf::Service *service = it->second.m_service; // 获取 service 对象
const google::protobuf::MethodDescriptor *method = mit->second; // 获取 method 对象
// 生成 RPC 方法调用的请求 request 和响应 response
google::protobuf::Message *request = service->GetRequestPrototype(method).New();
// 利用 request 对调用方法所需要的实际参数进行反序列化
if (!request->ParseFromString(args_str)) {
std::cout << "request parse error, content:" << args_str << std::endl;
return;
}
google::protobuf::Message *response = service->GetResponsePrototype(method).New();
/**
* 给下面 method 方法的调用,绑定一个 Closure 回调函数,需要完成序列化和反向发送请求的操作
* Closure 是 protobuf 提供的泛型回调接口(类似函数指针)
* 当业务方法执行完时,会自动调用 SendRpcResponse,将 response 序列化并通过 TCP 发送回客户端
* 这种回调机制的好处是:业务逻辑和网络通信解耦,业务只负责设置好 response,真正发送由框架自动处理
*/
google::protobuf::Closure *done =
google::protobuf::NewCallback<RpcProvider, const muduo::net::TcpConnectionPtr &, google::protobuf::Message *>(
this, &RpcProvider::SendRpcResponse, conn, response);
// 真正调用方法
service->CallMethod(method, nullptr, request, response, done);
/**
* CallMethod 动态分发机制:为什么可以通过 service->CallMethod 来直接调用具体的业务方法?
* 我们注册的 service 实例继承自 .proto 文件生成的 serviceRpc 类,而 ServiceRpc 又继承自 google::protobuf::Service
* 在 ServiceRpc 中重写了 Service 的纯虚函数 CallMethod,该函数内部会根据传入的 method 描述符自动调用对应的业务方法(如 Login)
* 而这些具体的业务方法(如 Login)又被我们用户自定义的 service 类重写了
* 所以当调用 CallMethod 时,实际上最终会执行我们在用户自定义的 service 类中实现的具体业务逻辑
*/
}为什么 CallMethod 方法可以调用到本地的方法?这个函数会因为多态实际调用生成的 pb.cc 文件中的 CallMethod 方法,代码如下:
switch (method->index()) {
case 0:
GetFriendsList(controller,
::PROTOBUF_NAMESPACE_ID::internal::DownCast<const ::fixbug::GetFriendsListRequest*>(request),
::PROTOBUF_NAMESPACE_ID::internal::DownCast<::fixbug::GetFriendsListResponse*>(response),
done);
break;
default:
GOOGLE_LOG(FATAL) << "Bad method index; this should never happen.";
break;
}这个函数和上面讲过的 FiendServiceRpc stub::GetFriendsList 方法相似,都是通过 xxx->index 来调用实际的方法。正常情况下会触发case 0,然后会调用我们在 FiendService 中重写的 GetfiendsList 方法。
简单理解:就算我们没有重写 goole.:service中 的 callmethod,但是 protoc 生成的 serviceRpc 重写了 callmethod,当我们使用这个重写的 callmethod 调用 xxx 方法就会因为多态调用到我们 service 重写的 Getfiendslist 方法。
// 重写基类方法
void GetFriendsList(::google::protobuf::RpcController *controller,
const ::fixbug::GetFriendsListRequest *request,
::fixbug::GetFriendsListResponse *response,
::google::protobuf::Closure *done) {
uint32_t userid = request->userid();
std::vector<std::string> friendsList = GetFriendsList(userid);
response->mutable_result()->set_errcode(0);
response->mutable_result()->set_errmsg("");
for (std::string &name : friendsList) {
std::string *p = response->add_friends();
*p = name;
}
done->Run();
}这个函数的逻辑比较简单:调用本地的方法,填充返回值 response,然后调用回调函数 done->Run(),也就是我们前面注册的 Closure 类型回调函数。
google::protobuf::Closure *done = google::protobuf::NewCallback<RpcProvider, const muduo::net::TcpConnectionPtr &, google::protobuf::Message *>(this, &RpcProvider::SendRpcResponse, conn, response);在回调真正执行之前,我们的本地方法已经执行了并填充完返回值,那么我们还需要序列化返回结果并将序列化后的数据发送给对端。回调函数 done->Run() 就实现这个功能,它实际调用的是 RpcProvider::SendRpcResponse。
到这里,RPC 提供方的流程就结束了。
从时间节点来说,此时应该对端来接收返回值了,接收部分也就是在这一节最上面的 MprpcChannel::CallMethod 函数中的下半部分,将发过来的的数据反序列化即可。
目前我们的 RPC 是不支持异步的,因为在 MprpcChannel::CallMethod 方法中发送完数据后就会一直等待着接收。
注意:目前实现的 RPC 的网络通信采用的是 muduo 网络库,muduo 支持函数回调,即在对端发送信息来之后就会调用注册好的函数,函数注册代码在:
m_muduo_server->setMessageCallback(
std::bind(&RpcProvider::OnMessage, this,
std::placeholders::_1,
std::placeholders::_2,
std::placeholders::_3));个人贡献
- 跳表模块(SkipList):实现跳表数据结构,并基于 Boost Serialization 实现了数据的序列化/反序列化,确保其可以安全持久化;
- KV Server 模块:负责将上层客户端的操作转化为 Raft 日志,通过状态机最终落盘;
- RPC 通信系统:我用 protobuf 自己实现了一个简化版的 RPC 框架,完成 Raft 节点间的通信;
- 客户端交互模块:用于构造 Put/Get 请求并与集群交互,具备容错和重试机制
