概述(待修改)
线程池里有若干线程,每个线程里有三类协程:主协程、调度协程和任务协程。
多线程通过互斥锁拿取任务后,利用线程的局部变量(调度协程指针)各自调用子协程去做任务,互不干扰和影响并发的去执行任务。
调度线程默认情况下主协程就是调度协程,而 main 主线程的主协程和调度协程是分开的。
IO 协程调度器对 idle 空闲协程进行了重写,主协程只进行任务调度,idle 只监听 epoll 进行任务添加,降低了不同功能之间的耦合,便于后期扩展维护。(针对调度线程而言)
用到智能指针的场景
shared_ptr
// 线程池,存储初始化好的线程
std::vector<std::shared_ptr<Thread>> m_threads;使用 shared_ptr 的必要性:(即为什么不直接存储 Thread 对象或使用 unique_ptr)
- 共享所有权
shared_ptr允许多个模块共享同一个Thread实例,避免重复创建或销毁。- 线程对象可能在多个地方被使用,比如:
- 线程池需要管理线程对象的生命周期。
- 其他模块(例如调度器)需要持有某些线程的引用,以便与它们交互或控制它们。
- 生命周期管理
- 只要有一个
shared_ptr持有该对象,对象就不会被销毁。 - 线程对象的生命周期需要与调度器解耦(例如,调度器销毁后,线程可能仍在执行任务)。
- 只要有一个
- 避免悬挂指针
- 如果直接存储裸指针(
Thread*),当某个外部组件持有该指针时,若调度器先于该组件销毁,会导致悬挂指针。 shared_ptr通过引用计数保证对象的生命周期至少与所有持有它的shared_ptr一样长,避免悬挂指针问题。
- 如果直接存储裸指针(
thread
为了弥补协程的缺点,使用多线程配合多协程更好地利用 CPU 的多核资源
主要用于创建并管理底层线程,为协程提供运行环境,同时通过线程局部存储和同步机制,为协程调度提供必要支持,确保协程可以在合适的线程上被正确的调度和执行。
同步操作
利用互斥量和条件变量实现了信号量
// 用于线程方法间的同步
class Semaphore
{
private:
std::mutex mtx;
std::condition_variable cv;
int count;
public:
// 信号量初始化为0
explicit Semaphore(int count_ = 0) : count(count_) {}
/*
explicit 关键字用来修饰只有一个参数的类构造函数,以表明该构造函数是显式的,而非隐式的
当使用 explicit 修饰构造函数时,它将禁止类对象之间的隐式转换,以及禁止隐式调用拷贝构造函数
比如防止出现 Semaphore sem = 3,将数字3转换成 Semaphore 对象的这种情况,必须标准:Semaphore sem(3);
*/
// P操作
void wait()
{
std::unique_lock<std::mutex> lock(mtx); // 没有选择使用 lock_guard 是因为它不允许手动解锁,并且无法在 wait 中将锁释放,只能等待l ock_guard 函数结束
while (count == 0) { // 为了防止虚假唤醒,直到 count > 0 才跳出循环
/*
这里体现了 uique_lock 允许在 cv.wait(lock) 内手动解锁 mtx,而 lock_guard 不允许这样做
cv.wait(lock) 在等待时会自动释放 mtx,让其他线程可以获取锁并修改 count
当 cv.wait(lock) 满足条件变量的条件被 notify_one() 或 notify_all() 唤醒后
lock 会自动重新获取 mtx,确保 count-- 操作是安全的
*/
cv.wait(lock); // wait for signal
}
count--;
}
// V操作:负责给 count++,然后通知 wait 唤醒等待的线程
void signal()
{
std::unique_lock<std::mutex> lock(mtx); // 加锁
count++;
cv.notify_one(); // signal:注意这里的 one 指的不一定是一个线程,有可能是多个
}
};fiber
Fiber 类提供了协程的基本功能,包括创建、管理、切换和销毁协程。使用 ucontext_t 保存和恢复协程的上下文,并通过 function<void()> 来存储协程的执行逻辑(即入口函数)。
类比进程的就绪、阻塞等各种状态,定义三种协程的状态:就绪态、运行态和结束态,一个协程要么正在运行(RUNNING),要么已就绪(READY),要么运行结束(TERM)。
对于非对称协程来说,协程除了创建语句外,只有两种操作:resume 恢复执行和 yield 让出执行。协程的结束没有专门的操作(协程的函数运行完了即为协程结束),协程结束时会调用一次 yield 操作,从任务协程返回到主协程(调度协程)。
在实现协程时需要给协程绑定一个运行函数,并给每一个创建的协程分配内存空间(因为实现的是有栈协程,并采用独立栈思路)。
构造函数
Fiber 类提供带参和无参两个构造函数,带参构造函数用于构造子协程,无参构造函数用于初始化当前线程的协程功能。
带参构造函数
创建一个新协程并指定其入口函数、栈的大小和是否受调度,初始化 ucontext_t上下文,分配栈空间,并通过 make 将上下文与入口函数绑定。由于采取的是独立栈的形式,每个新协程都有自己固定大小的栈空间(注意:主协程没有独立栈,它运行在当前线程的栈上,不必分配一个新的独立栈)。
无参构造函数
这个函数被定义为私有的成员函数,不允许在类外调用,只能通过 GetThis() 方法进行调用。
作用是初始化当前线程的协程功能,即构造线程的主协程对象,以及对变量 t_fiber(正在运行的协程)、t_thread_fiber(主协程)、t_scheduler_fiber(调度协程)进行赋值。
在使用协程之前必须调用一次 GetThis(),目的是初始化主协程和调度协程(默认主协程充当调度协程,这里是针对调度线程而言)。
resume / yield
resume
在非对称协程中,执行 resume 要分两种情况:
- 成员变量 m_runInScheduler 为 true,说明该子协程受调度协程的调度。使用 swapcontext 函数保存此时线程的局部变量的调度协程的上下文,然后激活线程局部变量的子协程去执行任务,也就是由调度协程 t_scheduler_fiber 切换到该协程恢复执行。
- 成员变量 m_runInScheduler 为 false,说明该子协程不受调度协程的调度。此时的执行过程就是保存主协程的上下文,激活子协程,这个过程就不需要调度协程进行参与了。(调度线程默认情况下主协程就是调度协程,而 main 主线程的主协程和调度协程是分开的)
yield
同 resume,根据 m_runInScheduler 来判断此时的 yield 是由哪个协程到哪个协程
- 如果 m_runInScheduler 为true,代表该协程受调度协程的调度,因此保存子协程的上下文,将执行权切换给调度协程
- 如果为false,则保存子协程的上下文,将执行权切换给主协程
reset 函数
复用一个已终止的协程对象:重置协程的入口函数,重新设置上下文,将协程状态从 TERM 改为 READY,从而避免频繁创建和销毁对象带来的开销(在有协程池的情况下,就会频繁调用该函数)。
scheduler
在 scheduler 类中,由于一开始没有任务,所以是主协程和调度协程(也可以理解成子协程)在互相切换。当有任务来了,此时子协程(任务协程)去调用 resume,SetThis 将表示当前运行的协程的 t_fiber 变量设置为子协程。然后记录调度协程的上下文(方便 yield 的时候切回去),激活子协程上下文,运行子协程即可。
简单来说:没事的时候就是主协程和调度协程玩,等到有任务了就让调度协程和子协程玩。
协程调度器
调度器创建后,内部首先会创建一个调度线程池。调度开始后,所有调度线程按顺序从任务队列里取任务执行,调度线程数越多,能够同时调度的任务也就越多。当所有任务都调度完后,调度线程就停止下来等新的任务进来。
添加调度任务的本质就是往调度器的任务队列里塞任务,并且要通知调度线程有新的任务来了。对于调度器来说,除了协程,函数也是调度器需要调度的任务。因为协程本身就是函数和函数运行状态的组合,但在实际运行中还是要先把函数包装成协程,协程调度器的实现重点还是以协程为主。
调度器内部维护一个任务队列和一个调度线程池,调度算法采用先来先服务算法。开始调度后,线程池中的调度线程从任务队列里按顺序取任务执行,调度线程可以包含 caller 线程(即 main 函数所在的线程,因为在 main 函数中创建的调度器)。当全部的任务执行完成后,调度器停止调度,等待新的任务到来。当新的任务到来,通知线程池重新开始运行调度。当真正停止调度时,各调度线程退出,调度器停止工作。
调度时的协程切换问题
1.若主线程不参与调度
即当 use_caller 为 false 时,主线程不参与调度,因此需要创建新的调度线程。调度线程的入口函数会启动调度协程(主协程),该调度协程负责从任务队列中取任务,并切换到子协程执行。
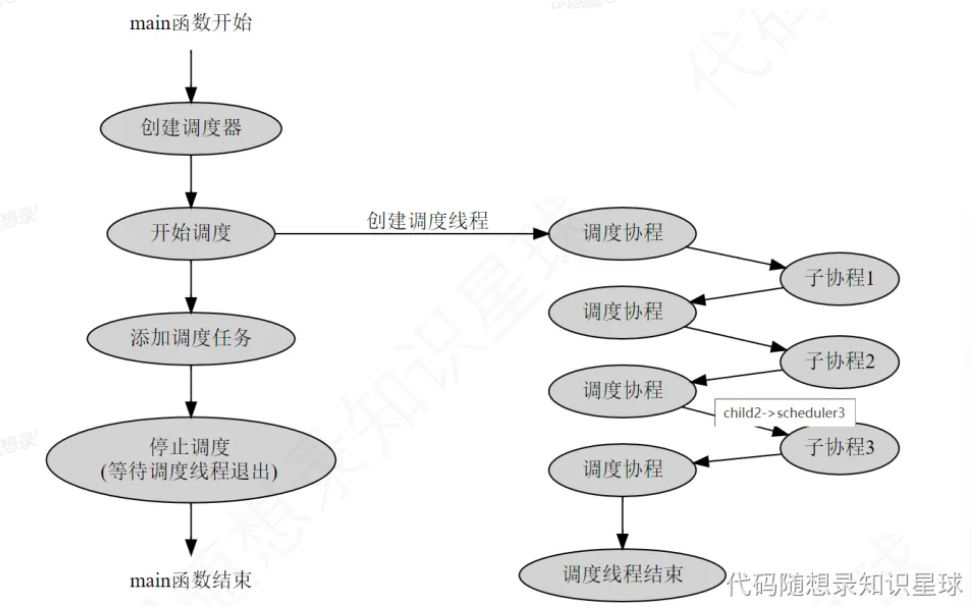
main 主线程(也就是调度器线程)不参与协程的调度,它要做的是创建调度器,将任务添加到调度器中的任务队列中,并在适当的时机停止调度器。当调度器停止时,main 函数要等待所有调度线程结束后再退出。
新创建的调度线程(线程池中的)启动后会运行调度器的主循环,负责从任务队列中取出任务并判断 m_runlSchedluer 的值。若为 true 就是新线程的调度协程和子协程进行上下文的切换,若为 false 则是新线程的主协程和子协程进行上下文切换。
2.若主线程也参与调度
use_caller 为 true 时,可以是多线程,也可以是单线程。如果是多线程,那么就和上面一样,只不过不一定需要创建另外的线程作为调度线程了。现在可以是主线程充当调度线程,那么它除了切换上下文去执行子协程任务外,还负责了任务的分配和调度器的停止,也就是主线程的功能变多了。
如果是单线程,且 main 主线程参与调度:
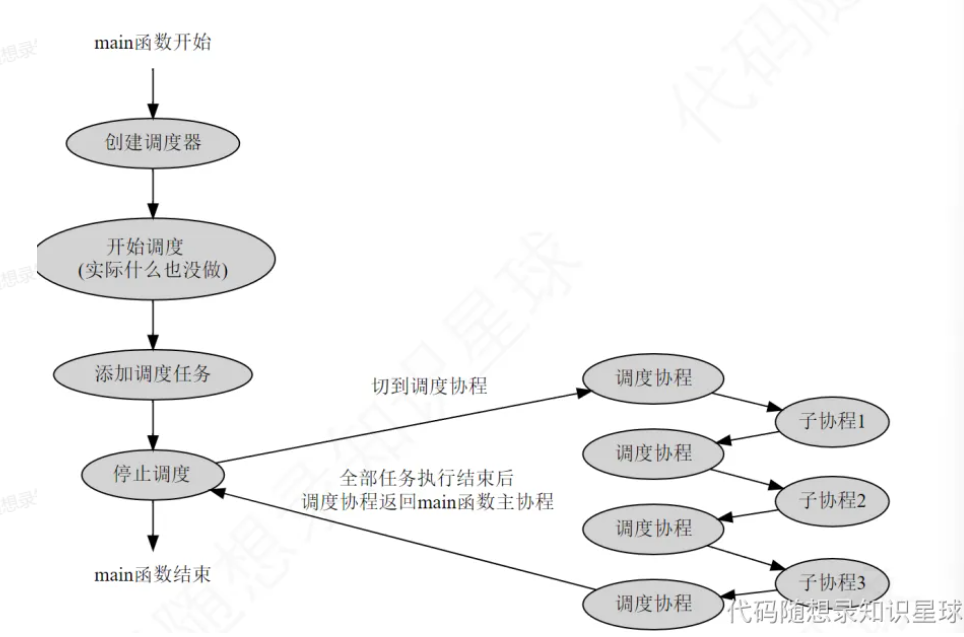
main 函数所在的主线程中有三类协程:
- main 函数对应的主协程
- 调度协程
- 待调度的任务协程
这三类协程的运行顺序如下:
- main 函数主协程运行,创建调度器,并向调度器添加任务。
- 开始协程的调度,主协程让出执行权给调度协程,调度协程按顺序调度任务队列中的所有任务。
- 每次执行一个任务,调度协程都要让出执行权,切到该任务的协程里去执行。任务执行结束后,再切回到调度协程,继续下一个任务的调度。
- 所有任务都执行完后,调度协程让出执行权并切回 main 函数的主协程,以保证程序的顺利结束。
总体的过程:main 创建调度器 -> 添加任务 -> 主协程切换到调度协程 -> 从任务队列按顺序拿取任务 -> 调度协程切换到子协程 -> 执行任务 -> 子协程切换到调度协程 -> 继续下一个任务的调度 -> ······ -> 所有任务都被调度执行完 -> 调度协程切换到主协程
在具体实现上,sylar 的子协程只能和主协程切换,而不能和另一个子协程(比如调度协程)切换。因为两个子协程相互切换,上下文都会变成子协程的,主协程却没有保存就切换不回去了。这代表 sylar 主线程的主协程既要创建调度器,监听事件添加到任务队列,又要充当调度协程的作用,切换到子协程执行任务。也就是说,主线程的主协程任务很重。
而本项目使用主协程+调度协程+任务协程(即有两类子协程)的设计思路,有更好的灵活性和拓展性,如何解决上述问题?
只需要给每个线程增加一个线程局部变量(调度协程的 Fiber 指针),用于保存调度协程的上下文。这样每个线程可以同时保存三个协程的上下文,协程就能根据自己的身份来选择和哪个协程进行切换,具体的:
- 给协程类增加一个 bool 类型的成员 m_runInScheduler,用于记录该协程是否受调度器的调度。
- 创建协程时,根据协程的身份指定对应的协程类型:想被调度器调度的协程的 m_runlScheduler 设为 true,线程主协程和调度协程的 m_runnInScheduler 设为 false。
- resume 一个协程时,如果这个协程的 m_runnInScheduler 为 true,表示这个协程受调度器的调度。那么此时这个协程就应该和三个线程局部变量中的调度协程进行切换;同理,在 yield 时,也应该恢复调度协程的上下文,表示子协程切回到调度协程。
- 如果协程的 m_runnInScheduler 为 false,表示这个协程不受调度器的调度。那么在 resume 协程时,直接和主协程切换即可,相当于默认不去使用调度协程。
也就是说,在 use_caller 为 true 的情况下:主线程的主协程创建调度器,监听事件并向调度器添加任务;调度协程从任务队列中取出任务(本质是协程)并切换到任务协程去执行;任务协程就执行任务。三类协程各司其职,降低了不同功能之间的耦合,便于后期扩展维护(这也是本项目相较于 sylar 的优化之一)。
timer
实现了定时器(Timer)和定时器管理器(TimerManager),主要用于管理定时任务,支持在设定的时间后执行某些操作,并且可以管理多个定时器,比如添加、删除、刷新等操作。
为什么要做定时器:为了实现协程调度器对定时任务的调度,服务器上经常要处理定时事件,比如3秒后关闭一个连接,或是定期检测一个客户端的连接状态。
无论是升序链表还是时间轮的设计都依赖一个固定周期触发的 tick 信号,比如三秒为一个标准触发信号,然后检查是否有超时定时器,如果没有就继续等下一个三秒。
这样的设计比较笨拙且精确度低,还有另外一种设计思路:
每次取出所有定时器中超时时间最小的超时值作为一个 tick 信号,一旦 tick 触发,超时时间最小的定时器必然到期。处理完已超时的定时器后,再从剩余的定时器中找出超时时间最小的一个,并将这个最小时间作为下一个 tick,如此反复,就可以实现较为精确的定时。
本项目使用的是最小堆(具体实现用的是 std::set),因为可以很快的获取到当前最小超时时间,所有的定时器根据绝对的超时时间点进行排序,每次取出离当前时间最近的一个超时时间点,计算出超时需要等待的时间,然后等待超时。超时时间到后,获取当前的绝对时间点,然后把最小堆里超时时间点小于等于这个时间点的定时器都收集起来,执行回调函数。
为什么是“把最小堆里超时时间点小于等于这个时间点的定时器都收集起来“,难道不是只有一个定时器到期吗?因为当时只”取出离当前时间最近的一个超时时间点“。
| 定时器ID | 超时时间点 |
|---|---|
| Timer A | 1000ms |
| Timer B | 1000ms |
| Timer C | 1500ms |
| Timer D | 2000ms |
为什么等待过程中可能有多个定时器同时到期?
- 多个定时器可能有相同的超时时间:
- 例如两个定时器
A和B都设定在1000ms超时 - 当
tick触发时,它们都应该同时执行
- 例如两个定时器
- 线程的调度延迟:
- 例如
tick预计在1000ms触发,但因为某些原因(比如系统调度或负载高),实际代码运行时已经到了1020ms - 此时,所有超时时间 ≤
1020ms的定时器都应该执行,而不仅仅是1000ms的那个
- 例如
假设当前时间 t=900ms,tick 触发后,计算出 100ms 后应该超时,于是线程 sleep(100ms)
在 t=1000ms 时,超时触发:
- 取出
1000ms这个最小的超时时间点 - 检查所有小于等于
1000ms的定时器(即A和B),它们都已经到期 - 执行
A和B的回调函数 - 取最小堆剩下的下一个最小时间点
1500ms作为新的 tick 目标
所以,不一定只有一个定时器到期,而是所有超时的定时器都应该执行。
在注册定时事件时,一般提供的是相对时间,比如相对当前时间 3s 后执行。需要根据传入的相对时间和当前的绝对时间计算出定时器超时的绝对时间点,然后根据这个绝对时间点对定时器进行排序。因为依赖的是系统绝对时间,所以需要考虑校时的因素。
定时器的超时等待基于 epoll_wait,精度为毫秒级(因为 epoll_wait 的超时精度也只有毫秒级)。IO 协程调度器会在调度的空闲时阻塞在 epoll_wait 上,等待 IO 事件发生。原生 epoll_wait 具有固定的超时时间(5s),加入定时器的功能后 epoll_wait 的超时时间改为当前定时器的最小超时时间。epoll_wait 返回后,根据当前的绝对时间把已超时的所有定时器收集起来,执行它们的回调函数。
那么 epoll_wait 触发一定是超时了吗?
由于 epoll_wait 的返回并不一定是超时引起的,也可能是 IO 事件唤醒的,所以在 epoll_wait 返回时不能想当然的以为是定时器超时,可以通过比较当前的绝对时间和定时器的绝对时间,就可以判断出定时器到底有没有超时。
epoll_wait 不只负责监听 I/O 事件,还负责监听等待定时器。
关键函数
/**
* 将一个新定时器,添加到定时器管理器中,并在必要时唤醒线程
* 详细来说:epoll_wait 不只负责监听 I/O 事件,还负责等待定时器
* epoll_wait 是“带超时阻塞”的,并且是按最早超时定时器设置的 timeout,如果你加入了一个更早的定时器,
* 必须唤醒 epoll_wait,重新设置它的 timeout,否则会错过定时器的触发时机
*/
std::shared_ptr<Timer> TimerManager::addTimer(uint64_t ms, std::function<void()> cb, bool recurring)
{
std::shared_ptr<Timer> timer(new Timer(ms, cb, recurring, this));
addTimer(timer);
return timer;
}
void TimerManager::addTimer(std::shared_ptr<Timer> timer)
{
bool at_front = false;
{
std::unique_lock<std::shared_mutex> write_lock(m_mutex); // 独占写锁
// std::pair<iterator, bool> insert(const value_type& val);
// insert 返回值为 pair,取 first 是为了获取迭代器
auto it = m_timers.insert(timer).first;
// 检查新插入的定时器是否排在最前面(即下一个要触发的定时器)
at_front = (it == m_timers.begin()) && !m_tickled;
// 如果排在最前面,并且没有唤醒过调度线程
if(at_front)
{
m_tickled = true; // 标记已经触发过唤醒,避免重复唤醒,提高性能
}
}
if(at_front)
{
// 唤醒 epoll_wait 或 IO 调度器中的线程
onTimerInsertedAtFront();
}
}读写锁实例
// 取消一个定时器,删除该定时器的回调函数并将其从定时器堆中移除
bool Timer::cancel()
{
/**
* std::shared_mutex 是 C++17 引入的一种读写锁,支持:
* 1.共享锁(std::shared_lock):多个线程可以同时读取,但不能写入
* 2.独占锁(std::unique_lock):只能有一个线程写入,其他线程必须等待
* unique_lock / shared_lock / lock_guard 都是标准库提供的互斥锁 RAII 封装工具
* unique_lock 用于获取 shared_mutex 的写锁,它会独占 shared_mutex,让当前线程获得写权限,其他线程无法同时写入
* shared_lock 用于获取 shared_mutex 的读锁,它会共享 shared_mutex,让多个线程获得读权限,支持多个线程同时读取
* 相比于 lock_guard,unique_lock 更灵活,支持手动解锁
*/
// m_manager->m_mutex 是 shared_mutex 类型,支持读写锁(共享锁和独占锁)
// 使用 unique_lock 获取 m_manager->m_mutex 的独占写锁,确保当前线程可以独占访问 m_manager 保护的资源,而其他线程必须等待
std::unique_lock<std::shared_mutex> write_lock(m_manager->m_mutex); // 写锁互斥锁
if(m_cb == nullptr)
{
return false;
}
else
{
m_cb = nullptr; // 将回调函数设置为 nullptr
}
auto it = m_manager->m_timers.find(shared_from_this()); // 从定时管理器中找到需要删除的定时器
if(it != m_manager->m_timers.end())
{
m_manager->m_timers.erase(it); // 删除该定时器
}
return true;
}ioscheduler
IO 协程调度器是继承前面的协程协程调度器实现的,因此可以看成是增强版的协程调度。IO 协程调度支持为套接字文件描述符注册可读和可写事件,当监听到 fd 注册的事件触发时,执行对应的回调函数(正如之前提到的,回调函数会被包装为协程)。
ioscheduler 基于 epoll 实现,只支持 linux 平台。对于每个 fd,支持 EPOLLIN 可读事件和 EPOLLOUT 可写事件两类事件,并将 epoll 支持的其他事件,比如 EPOLLRDHUP(对端关闭连接),EPOLLERR(错误事件),EPOLLHUP(挂起事件)归类到 EPOLLIN 和 EPOLLOUT 中,也就是所有的事件都可以表示为可读或可写事件,甚至有的事件还可以同时表示可读和可写(比如 EPOLLERR 事件)。
IO 协程调度为什么都包含一个三元组信息?
对于 IO 协程调度,每次调度都包含一个三元组信息,分别是文件描述符、事件类型和回调函数,其中 fd 和事件类型用于 epoll_wait,回调函数用于协程调度。三元组信息通过 Fdcontext 结构体来存储,在执行 epoll_wait 时通过 epoll_event 的私有数据指针 data.ptr 来保存 Fdcontext 的结构体信息。
IO 协程调度器在 idle 时会 epoll_wait 所有注册的 fd,如果有 fd 满足条件,epoll_wait 返回,从私有数据中拿到 fd 的上下文信息,并且执行其中的回调函数(回调函数都会被封装为协程对象)(实际是 idle 协程只负责收集所有已触发的 fd 的回调函数并将其加入调度器的任务队列,真正的执行时机是 idle 协程退出后,调度器在下一轮调度时执行)。
读写锁实例
如果只是访问 m_fdContexts 数组就用读写锁的读锁即可,但是如果要修改共享资源数组的大小就要先解读锁再加写锁确保对资源的独立访问。
std::shared_mutex m_mutex; // 读写锁
std::shared_lock<std::shared_mutex> read_lock(m_mutex); // 触发读写锁的读锁
if((int)m_fdContexts.size() > fd) // 说明传入的 fd 在数组里面,将对应的 FdContext 赋值给 fd_ctx
{
fd_ctx = m_fdContexts[fd];
read_lock.unlock();
}
else // 没在数组里面,则重新分配数组的 size 来初始化 FdContext 的对象
{
read_lock.unlock();
std::unique_lock<std::shared_mutex> write_lock(m_mutex); // 触发读写锁的独占写锁
contextResize(fd * 1.5); // 扩容
fd_ctx = m_fdContexts[fd];
}unique_ptr 实例
在 epoll 事件循环中,events 数组仅在当前作用域内使用,不需要多个组件共享访问权,因此使用unique_ptr。
static const uint64_t MAX_EVNETS = 256; // 定义 epoll_wait 能同时处理的最大事件数
// 使用 std::unique_ptr 动态分配了一个大小为 MAX_EVENTS 的 epoll_event 数组,用于存储从 epoll_wait 获取的事件
std::unique_ptr<epoll_event[]> events(new epoll_event[MAX_EVNETS]);tickle 函数
epoll_wait 除了监听 IO 事件,还要监听定时器。如果一直没有 IO 事件发生,调度器所在协程会在 epoll_wait 上一直阻塞等待 ,即使定时器到期或有新任务加入队列,也无法及时响应。
例如,现在有一个 100ms 的定时器,到期后应该立即恢复执行,而不是等 epoll_wait 自然超时(可能还有几秒)。因此,tickle 函数的作用是:在 epoll_wait 阻塞期间,由于定时器超时而被触发,从而唤醒调度器立即处理待执行的任务。
通过写入一个字符到写管道 mtickleFds[1] 中,强制 epoll_wait 返回,唤醒调度器,使其立即检查任务队列并执行待处理任务。若没有 tickle,调度器可能因未感知到新任务而持续空转。本质是调度器的信号机制,其作用类似于操作系统的“中断”。
当定时器被插入到最小堆的最前面时,触发 tickle 事件,唤醒阻塞的 epoll_wait ,回收超时的定时任务(回调函数和协程)并放入协程调度器中等待调度。
idle 函数
- 首先定义
epoll_wait能同时处理的最大事件数为 256 个,然后使用std::unique_ptr events(new epoll_event[MAX_EVNETS])动态分配一块存储epoll_event类型数据的内存。 - 所有的步骤都在一个大的
while循环中,先检査有无debug或者stopping终止的情况,如果没有就再设立一个while循环进行epoll_wait的阻塞,等待 fd 读写事件的响应或者超时定时器超时或者有新的定时器插入到最小时间堆的堆顶从而触发tickle信号。注意:这里的epoll_wait的超时时间取的是epoll_wait原生超时时间 5000ms 和时间堆中的堆顶定时器超时时间的较小值。 - 当
epoll_wait从阻塞中被触发时,要么因为超时触发,要么注册的 fd 有响应的事件发生。首先通过listExpiredCb(cbs)获取所有超过定时器的回调函数,并逐个包装添加到协程调度的任务队列中。 - 处理完定时器,再处理 fd 的响应事件。遍历
epoll_wait返回的事件数组,获取一个个准备好的 event。由于 tickle 函数会向管道中写入从而唤醒epoll_wait,因此要先 while 循环不断读数据直到 read 返回 -1。其他情况就正常从 event 中找到当时存放在 event.data.ptr 中的 fd_ctx(文件描述符上下文)。 - 需要注意我们只定义了读 EPOLLIN 和写 EPOLLOUT,其他事件都要转换成这两个。接下来判断 fd_ctx->event 真实的事件是什么,计算除响应的该事件外剩下的事件,调用
epoll_ctl修改或删除epoll监听事件(如果没剩下事件就删除,反之修改,即删除一个事件)。最后调用triggerEvent函数触发响应事件。 idle主动yield让出控制权,使得主线程也可以和其他工作线程一样去执行任务。
hook
hook 的核心思想是:将阻塞调用拆解为“注册事件 + 主动让出”,通过调度器异步唤醒。
简单来说,hook 是对原 API 的同名封装,在调用这个接口时,首先考虑执行我们封装好的同名 API,而不是原 API。
即钩子类:旨在拦截并重定向某些系统调用,如与网络相关的 socket、connect、read、write 等函数。
这种技术通常用于网络库、异步 IO 操作或协程库中,以便对底层系统调用进行自定义处理,从而实现非阻塞 IO、超时控制或其他功能。
举个栗子:
使用协程调度器处理三个任务:
- 协程1:sleep(2) 睡眠 2s 后返回
- 协程2:在 socket fd1 上 send 100k 数据
- 协程3:在 socket fd2 上 recv 直到数据接收成功
如果在未使用 hook 的情况下,IO 协程调度器的流程如下:
- 先执行协程1,这样因为 sleep 的阻塞调用会暂停 2s,此时协程1被阻塞。
- 等到 sleep 结束后协程1让出控制权,执行协程2,这里会因为 send 等不到要发送的写资源一样陷入阻塞。
- 等到写资源来了,协程2才会让出执行权给协程3,但是此时又阻塞在 recv 的读上。
整个过程变成了一个阻塞且同步的框架,完全没有实现非阻塞协程的切换,为什么?
原因在于在子协程执行 resume 函数的时候先去执行 sleep(2),执行完后才 yield,那就需要阻塞在这个协程等待 2s。此时其他协程不能工作,只能等到协程1执行完让出执行权。因此,根本原因就是 sleep 函数内部无法 yield,因为没有改变函数内部的执行逻辑,函数内部不能进行 yield,所以只能一步步执行下去了。
所以使用 hook 封装,更改函数内部执行逻辑来解决这个问题。比如把 sleep(2) 改成两个动作:
- 注册定时器:向调度器插入一个2秒后触发的回调任务。
- 立即让出执行权:当前协程主动
yield,让调度器去执行其他任务。
两秒后定时器到期时,epoll_wait 触发,调度器会恢复该协程的执行,从而“模拟”出 sleep(2) 的效果,但全程无阻塞。
总而言之,在 IO 协程调度中对相关的系统调用进行 hook 封装,可以让调度线程尽可能得把时间片花在有意义的操作上,而不是浪费在阻塞等待中。
hook 的两种方式
- 侵入式:直接改造代码,将目标函数的入口点替换为自定义的代码,从而在函数执行之前或之后注入自定义的逻辑。
- 外挂式(本项目):不修改目标程序的源代码,而是通过外部动态库(
.so)在运行时拦截并替换目标函数。通过优先加载自定义的动态库,拦截并修改后面系统动态库中函数的行为,从而实现 hook 效果。
举个栗子,比如对 write 函数进行外挂式 hook 改造,将自定义的 write 函数编译成 libhook.so 动态库,通过设置 LD_PRELOAD 环境变量,将 libhook.so 设置成优先加载。
LD_PRELOAD="./libhook.so" ./a.outLD_PRELOAD 环境变量,它指明了在运行 a.out 之前,系统会优先把 libhook.so 加载到程序的进程空间,使得 a.out 运行之前,其全局符号表就已经有一个 write 符号,这样在后续加载 libc 共享库时,由于全局符号介入机制 libc 中的 write 符号不会再被加入全局符号表,所以全局符号表中的 write 就变成了我们自己的实现。
三类需要 hook 的 API
- sleep 延时接口,包括 sleep、usleep、nanosleep。对于这些接口的hook,只需要注册一个定时事件,然后 yield 让出执行权,在定时事件触发后再回来执行当前协程即可。
- socket IO 系列接口,包括 read、write、recv、connect、accept 等。这类接口的 hook 首先需要判断操作的 fd 是否为 scoket fd ,以及用户是否显式地对 fd 设置了非阻塞。如果不是 socket fd 或是用户显示设置过非阻塞模式,那么就不需要使用 hook 了,直接调用原始系统调用即可。如果需要 hook,那么首先要注册对应的读写事件,然后 yield 让出执行权让其他协程执行,等事件发生后再继续执行当前协程。
- socket、fcntl、ioctl、close 等接口,这类接口主要处理的是边缘情况,比如分配 fd 上下文,处理超时及用户显式设置非阻塞问题。这里需要提前实现 FdCtx 和 FdManager 两个类,前者用于管理与 fd 相关的状态和操作(比如记录 fd 的读写事件超时时间和非阻塞信息,非阻塞信息包括用户显式设置的非阻塞和 hook 内部设置的非阻塞),后者用于管理 FdCtx 对象的集合。
这三类 hook 逻辑,核心目的都是:判断是否应该由 IO 协程调度器接管系统调用,若接管则通过 epoll + 协程调度实现非阻塞逻辑,否则就直接调用原始系统调用。
如何实现 hook
C 函数原型声明与重定向,举个栗子:
typedef unsigned int (*sleep_fun) (unsigned int seconds); // 定义了一个返回值是 unsigned int,参数类型是 unsigned int 的函数指针
extern sleep_fun sleep_f; // 声明了一个外部变量,类型是 sleep fun,变量名为 sleep_f
sleep_fun sleep_f = sleep;// 将 sleep_f 指向 sleep 函数,后面我们可以把 sleep 改为我们自定义的函数
// 可以直接通过 sleep 调用该函数
unsigned int result = sleep_f(5); // 等价于调用 sleep(5)宏 HOOK_FUN(XX) 是一个宏展开机制,通过将 XX 依次应用于宏定义中的每一个函数名称来生成一系列相似代码,可以有效减少重复代码,提高代码的可读性和维护性。
#define HOOK_FUN(XX) \
XX(sleep) \
XX(usleep) \
XX(nanosleep) \
XX(socket) \
XX(connect) \
XX(accept) \
```
#define XX(name) name##_f = (name##_fun)dlsym(RTLD_NEXT, #name);
HOOK_FUN(XX)
#undef xx //提前取消 xx 的作用域符号解释:
name##_f:将name和_f拼接,生成变量名,比如sleep_f(name##_fun):生成函数指针类型,比如sleep_fun#name:把 name 变成字符串常量,比如"sleep"dlsym(RTLD_NEXT, #name):获取系统中下一层的原始函数地址RTLD_NEXT:是一个dlsym的特殊句柄,表示“获取下一个同名符号”,用于 hook 场景
举个栗子:将 sleep、usleep、nanosleep 等作为 name 传入 XX(name) 宏,就会展开成:
sleep_f = (sleep_fun)dlsym(RTLD_NEXT, "sleep");
usleep_f = (usleep_fun)dlsym(RTLD_NEXT, "usleep");
nanosleep_f = (nanosleep_fun)dlsym(RTLD_NEXT, "nanosleep");
socket_f = (socket_fun)dlsym(RTLD_NEXT, "socket");dlsym 是 Linux 提供的一个 API,用于在运行时获取动态链接库中的符号地址。RTLD_NEXT 的作用是获取下一个定义,即绕过自定义 hook 改造的函数。
因为我们使用了 hook 外挂式改变了本应该优先加载的 libc 共享库,全局符号表中已经有改造过的 sleep 了,此时如果想获取原始的 sleep 系统调用就需要借助 dlsym(从动态库中获取符号地址函数)和 RTLD_NEXT,二者结合就是搜索没被加载进来的 libc 共享库里的 sleep 原始系统调用,即执行 socket_f 函数就是调用原始系统调用 socket。
do_io 函数
该项目有一部分自定义的系统调用(比如 accept、read、recv、write、send 等)要将其参数放入 do_io 模板来做统一的规范化处理(其它自定义的系统调用就是一个个单独的逻辑)。
※do_io 函数处理流程:
- 是否启用 hook:如果没启用 hook,直接调用原始系统调用返回。
- 获取 fd 上下文:通过
FdMgr获取fd对应的上下文FdCtx,若无或已关闭,则直接返回错误。 - 判断是否需要 hook:如果不是 socket 或用户已经设置了非阻塞模式,说明不适合协程调度,直接调用原始系统调用。
- 准备超时控制信息:获取该 IO 操作对应的超时时间,同时准备一个
timer_info用于后续处理。 - 执行原始 IO 操作:初次尝试调用,若遇
EINTR(中断)则重试。 - 如果返回
EAGAIN(资源暂时不可用):- 设置一个超时定时器(如果设置了超时时间),防止长时间阻塞。
- 使用
IOManager注册事件监听器(如读/写事件),并将当前协程 yield,让出执行权。 - 一旦事件触发或超时,epoll_wait 唤醒,协程回来继续执行。
- 协程恢复后判断状态:
- 如果因超时恢复,设置 errno 并返回错误。
- 如果是正常事件唤醒,则再次 retry 尝试 IO 操作。
- 最终返回 IO 调用结果。
协程和超时机制保证了可靠性和健壮性,具体在于如果出现资源暂时不可用,我们就注册新事件监听,然后主动 yield 让出执行权,当定时器超时或者资源满足就会唤醒 epoll_wait,将任务放入到调度器中执行,然后取消相应定时器,这就是 do_io 函数的作用。
weak_ptr 实例
std::shared_ptr<sylar::Timer> timer; // 声明一个定时器对象
std::shared_ptr<timer_info> tinfo(new timer_info); // 创建一个追踪定时器是否取消的对象
std::weak_ptr<timer_info> winfo(tinfo); // 判断追踪定时器对象是否存在va_list 可变参数
在使用 va_list 处理可变参数时,必须一个一个地按顺序取出每个参数。
int ioctl(int fd, unsigned long request, ...)
{
va_list va; // 声明一个 va_list 类型的变量,用于访问可变参数
va_start(va, request); // 初始化 va,使其指向可变参数列表中的第一个可选参数(request 之后的参数)
void* arg = va_arg(va, void*); // 从参数列表中取出下一个参数(void* 类型),赋值给 arg
va_end(va); // 清理 va 占用的资源,结束对可变参数的访问
...
}
测试
可以发现在使用多核资源的情况下,性能是超过原生 epoll 的。具体的差异可以查看测试结果中的 Requests per second(吞吐率),协程库和原生 epoll 的 rps 分别是 8064.96 和 7832.78。但是相较于原生 epoll,协程库还是有不少的用户态消耗。
即使在单线程的情况下,协程也能实现异步非阻塞编程。协程可以通过调度机制在 I/O 等待期间主动让出控制权,使同一线程内的多个协程交替执行,从而高效处理大量并发任务。相比于多线程模型,协程避免了线程上下文切换的开销,并显著降低了内存占用。
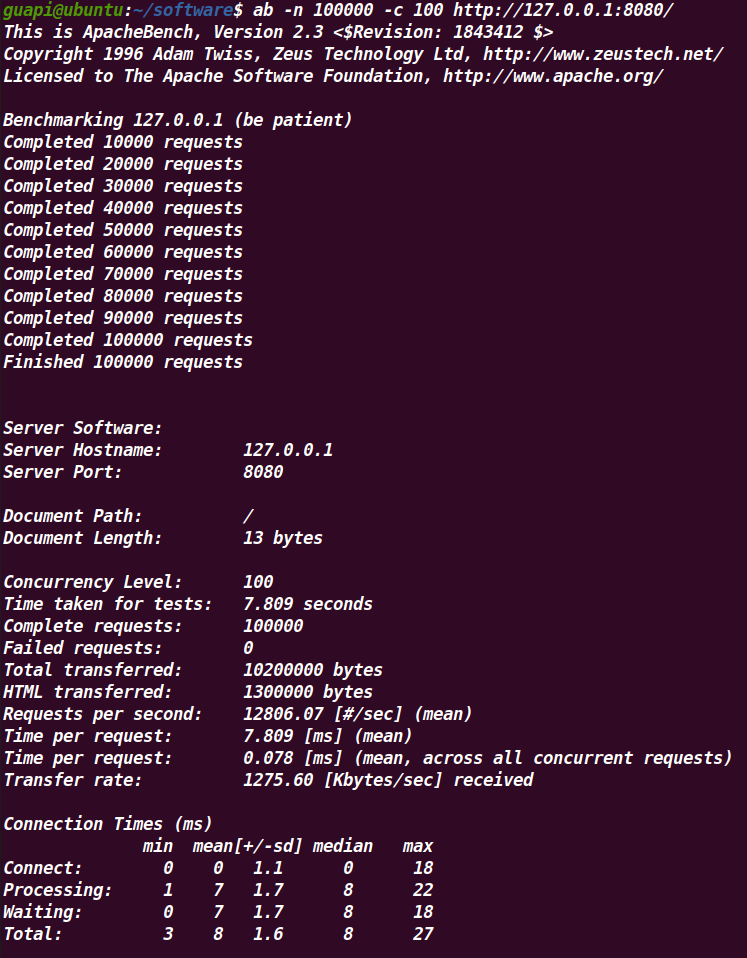
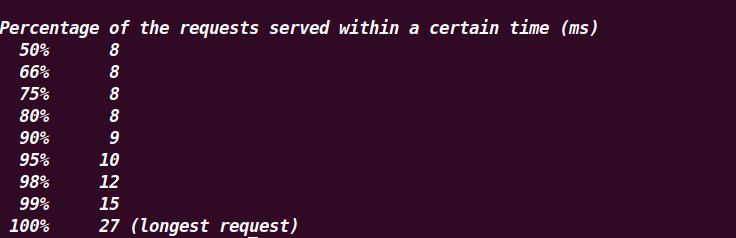
补充
协程
协程是一种执行过程中能够 yield 暂停(让出执行权)和 resume 恢复的子程序,也可以说协程就是函数和函数运行状态的组合。正常的函数在执行过程中就直接执行完成了,中间不会有多余的步骤,更不会说一个线程执行这个函数执行到一半就转头去执行其他函数了。但是协程不一样,使用协程首先要绑定一个入口函数,并且可以在函数的任意位置暂停去执行其他函数,之后再回来执行暂停的函数,所以说协程是函数和函数运行状态的组合(协程需要绑定入口函数,协程记录了函数的运行状态)。
协程是如何做到让函数暂停和恢复的?
协程会记录协程上下文,协程执行 yield 的时候协程上下文记录了协程暂停的位置,当 resume 的时候就从暂停的地方恢复。协程上下文包含了函数在当前状态的全部 CPU 寄存器的值,这些寄存器记录着函数的栈帧、代码执行的位置等信息,如果把这些信息交给 CPU 去执行就能实现从函数暂停的地方去恢复执行。需要注意在单线程的情况下,协程的 resume 和 yield 一定是同步的,一个协程进行 yield,必然对应另一个协程的 resume,因为线程不能没有执行主体。
协程的 yield 和 resume 是应用程序控制的,这点和线程不一样,线程的运行和调度是操作系统来完成的,因此协程也叫做用户态线程、轻量级线程。
分类
- 分类一:
- 对称协程
- 非对称协程
- 分类二:
- 有栈协程
- 独立栈(本项目采用该方案)
- 共享栈
- 无栈协程
- 有栈协程
对称协程与非对称协程
对称协程和非对称协程是协程的一种分类,它们的区别主要在于协程的切换方式和控制流的管理。
对称协程:
- 定义:各个对称协程之间可以直接相互调用和切换,控制流可以在多个协程之间自由转移。即协程之间是平等的,它们可以相互调用对方,每个协程可以显式地决定将控制权转移到哪个协程。
- 特点:
- 自由切换:协程可以显式地将控制权转移给其他协程。
- 平等地位:所有协程在调度时没有层级的关系,彼此平等。
- 复杂性:因为可以任意地切换协程,可能会让程序变得很复杂。
- 使用场景:
- 复杂多任务协作:多个任务需要频繁切换,共同协同完成一个目标。
- 状态机驱动系统:当有多个状态需要彼此直接切换,避免中间步骤。
- 需要频繁切换的计算密集型任务:特别适合高性能场景,例如游戏开发,一个任务可以主动切换到另外一个。
非对称协程:
- 定义:非对称协程出现了类似堆栈的调用方和被调用方,也就是出现了层级关系。比如A调用了B,B作为被调用方,在其 yield 后就会将执行的控制权交给A,而不是其他协程。
- 适用场景:
- IO 密集型应用:通常需要等待多个 IO 事件完成,例如 web 服务器中的请求处理和数据库读写。
- 任务调度:在多线程或任务调度中,协程由一个中心调度器进行调度,这样可以统一处理任务切换,例如 web 服务框架中的请求/响应循环。
- 简单的生产者消费者:比如在异步事件循环中,非对称协程的启动、暂停、恢复由调度者控制,结构清晰,避免了协程之间的相互依赖。
小总结:对称协程更灵活,非对称协程更简单。对于对称协程而言,不仅要绑定自己的入口函数来运行,还需要决定下一个执行的协程进行切换,相当于每个协程都做了协程调度器的工作。而在非对称协程中,可以设计专门的调度器来负责调度协程,每个协程只需运行自己的入口函数,然后结束时将运行权交回给调度器,由调度器来选出下一个要执行的协程即可。
有栈协程与无栈协程
两者的区别在于是否使用独立的调用栈来保存协程的上下文信息。
- 有栈协程(比如 Go 语言的协程)使用独立的调用栈来保存协程的上下文信息(当前状态全部寄存器的值)。当协程被 yield 挂起时,有栈协程会保存当前的执行状态(例如函数调用栈、局部变量、传递的参数等),并将控制权交还给调度器。当协程被恢复时,调用栈会将之前保存的协程状态恢复,从上次挂起的地方继续执行。类似于内核态线程的实现,不同协程间切换要切换对应的栈上下文,只是不用陷入内核而已。
- 无栈协程(比如 C++20 引入的协程)不需要独立的调用栈来保存协程的上下文信息,协程的上下文都放到公共内存中。当协程被 yield 挂起时,无栈协程会将状态保存在堆上的数据结构中,并将控制权交还给调度器。当协程被恢复时,无栈协程会将之前保存的状态从堆中取出,并从上次挂起的地方继续执行。协程的切换使用状态机来实现,不用切换对应的上下文,比有栈协程要轻量许多。
有栈和无栈的一个区别是看能不能任意地保存并切换嵌套函数,因为无栈协程不切换调用栈,所以无法做到嵌套多个函数还能像有栈协程一样切换。
独立栈与共享栈
独立栈和共享栈都是有栈协程。
- 共享栈就是所有的协程在运行时都使用同一个栈空间,每次协程切换时要把自己用的共享栈空间拷贝。协程调用 yield 的时候,该协程栈内容暂时保存起来,保存的时候需要用到多少内存就开辟多少,这样就减少了内存的浪费;resume 该协程的时候,协程之前保存的栈内容,会被重新拷贝到运行时的栈中。
- 独立栈就是每个协程的调用栈空间都是独立的(注意区分开调用栈和栈,前者是有栈协程的概念,后者是个函数都需要用到栈,不然局部变量、函数参数往哪存),且固定大小。优点是协程切换的时候,内存不用拷贝来拷贝去。而缺点是内存空间浪费,因为栈空间在运行时不能随时扩容,否则如果有指针操作了栈内存,扩容后将导致指针失效。为了防止栈内存不够,每个协程都要预先开一个足够的栈空间使用,很多协程在实际运行中用不了这么大的空间,就必然造成内存的浪费和开辟大内存造成的性能损耗。
总结:
- 所有共享栈使用公共内存,节省了内存,但是协程切换需要频繁进行内存的拷贝,影响 CPU 性能。
- 独立栈相对简单,但容易造成内存空间的浪费。
优缺点
优点:
- 高效资源利用:协程比线程更轻量,相较于协程,一个线程的创建和上下文切换开销较大。
- 简化异步编程:使用协程来写异步程序看起来就好像在写同步的代码,提升代码的可读性和维护性。
- 非阻塞操作:协程执行非阻塞操作,使得程序可以在等待 IO 或其他耗时操作时继续执行其他任务,提高了程序的并发性和响应性。
- 适用于高并发场景:由于协程开销小,适合处理大量的并发任务,如网络请求或高并发的 IO 操作。
缺点:
- 调试困难:由于协程涉及异步和延迟执行,调试和跟踪问题可能会比同步代码更复杂,尤其是多个协程交互时。
- 复杂的管理:协程的高级特性(如协程调度、优先级管理等)需要额外的调度器或框架支持,这可能会增加系统的复杂性。
- 协程状态管理:在协程之间共享和管理状态可能会引入复杂性,需要仔细设计避免数据竞争和一致性的问题。
- 无法利用多核资源:线程才是系统调度的基本单位,单线程下的多协程本质上还是串行执行的,只能用到单核计算资源,所以协程往往要与多线程、多进程一起使用。
- 线程可以直接由操作系统调度,操作系统可以将不同线程分配到不同的 CPU 核上并行执行,因此线程级别的并发可以利用多核资源。而由应用程序直接控制的调度是无法指定和分配到具体的 CPU 核上的,比如应用程序可以创建、销毁、控制线程等,但这些都是逻辑上的控制,操作系统才是线程实际运行的管理者,决定了线程什么时候运行,以及分配到哪个 CPU 核心上运行。
- 协程实际上是依附在线程上的,并且完全由应用程序控制。CPU 核的使用取决于线程的数量,如果是单线程,哪怕有多个协程也无法利用 CPU 的多核心资源。因为单线程只能被分配到一个 CPU 核上,哪怕此时有多个协程也只能等待一个协程 yield 后,另一个协程才能执行 resume。
ucontext 族函数
Linux 下的 ucontext 族函数是 GNU C 库提供的一组创建、保存、切换用户态执行上下文的 API,这是有栈协程能够随时暂停、恢复和切换的关键,通常用于实现非对称协程的实现。(不过高性能的协程往往会使用更底层的汇编语言来实现)
/**
* 用户态上下文结构体(平台相关,不同CPU的寄存器不同)
* 4个核心成员如下:
*/
typedef struct ucontext_t {
struct ucontext_t *uc_link; // 当前协程结束后,下一个要恢复的协程上下文(类似函数返回地址)
sigset_t uc_sigmask; // 当前上下文的信号屏蔽字(阻塞哪些信号)
stack_t uc_stack; // 当前协程的运行时栈空间(需手动分配内存)
mcontext_t uc_mcontext; // 平台相关的寄存器值(如PC、SP等)
// ... 其他平台扩展成员
} ucontext_t;
/*===== 上下文操作API =====*/
// 获取当前的上下文,保存当前执行状态到 ucp 中(类似于存档)
int getcontext(ucontext_t *ucp);
// 直接跳转到 ucp 保存的上下文对应的函数中执行(类似于读档)
int setcontext(const ucontext_t *ucp);
/**
* 配置协程入口函数和运行环境
* @param ucp getcontext获取的上下文
* @param func 协程入口函数
* @param argc func的参数个数
* @param ... func的具体参数
*
* 关键要求:
* 1. 必须提前为 ucp->uc_stack 分配栈内存
* 2. 若设置了 uc_link,func 执行完毕后(即该协程执行完毕后)会自动跳转到 uc_link 指向的上下文
* 3. 若未设置 uc_link,func 末尾必须手动调用 setcontext/swapcontext 以指定一个有效的后继上下
文,好让该协程结束后切换过去,否则程序就跑飞了
* 4. makecontext 执行后,ucp 会与函数 func 绑定,调用 setcontext(ucp) 或 swapcontext(&old, ucp) 时,程序会从 func 的入口点开始执行。
*/
void makecontext(ucontext_t *ucp, void (*func)(), int argc, ...);
/**
* 协程切换的核心 API
* @param oucp 保存当前上下文到此处(类似存档)
* @param ucp 跳转到目标上下文(类似读档)
*
* 典型流程:
* 1. 协程A调用 swapcontext(&ctx_A, &ctx_B) 保存自己,切换到B
* 2. 协程B通过 swapcontext(&ctx_B, &ctx_A) 切换回A
*/
int swapcontext(ucontext_t *oucp, const ucontext_t *ucp);补充:ucontext_t 中的 uc_mcontext 成员是实现协程上下文保存和恢复的关键,通过保存 PC 指针和调用栈指针来实现。当一个协程 yield 时,系统会保存当前的处理器状态到 uc_mcontext 中,包括所有的寄存器值和其他必要的处理器状态信息。当需要 resume 这个协程时,系统会将 uc_mcontext 中保存的状态重新加载到处理器寄存器中,从而恢复上下文,继续执行该协程。
